
Notice
Recent Posts
Recent Comments
Link
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | |||
| 5 | 6 | 7 | 8 | 9 | 10 | 11 |
| 12 | 13 | 14 | 15 | 16 | 17 | 18 |
| 19 | 20 | 21 | 22 | 23 | 24 | 25 |
| 26 | 27 | 28 | 29 | 30 |
Tags
- 프리티어
- 전국대학생게임개발동아리연합회
- 라피신
- Redis
- NAT gateway
- AWS
- 오블완
- 백엔드개발자
- openAI API
- 개발공부
- Spring boot
- spring ai
- Route53
- 게임개발동아리
- UNICON2023
- 42서울
- 인프라
- EC2
- 티스토리챌린지
- 캡스톤디자인프로젝트
- CICD
- 체크인미팅
- 스프링부트
- UNIDEV
- bastion host
- UNICON
- 프롬프트엔지니어링
- 프로그래밍
- 도커
- 생활코딩
Archives
- Today
- Total
Hyun's Wonderwall
[MongoDB, Colab] 구글 스프레드시트와 DB 연동으로 데이터 쉽게 삽입하고 업데이트하기 본문
먼저, 구글 Colab을 열고 새 노트북을 생성한다.
파이썬과 몽고DB를 연동하기 위해 pymongo를 설치한다.
!pip install gspread pandas pymongo
구글 드라이브를 마운트한다.
from google.colab import drive
drive.mount('/content/drive')
인증 절차를 진행한다.
from google.colab import auth
auth.authenticate_user()
import gspread
from google.auth import default
creds, _ = default()
gc = gspread.authorize(creds)
스프레드시트 파일을 연다.
worksheet = gc.open('스프레드시트 파일명').sheet1
데이터프레임에 불러와 저장한다.
import pandas as pd
data = worksheet.get_all_records()
df = pd.DataFrame(data)
df.head()
불러와진 결과를 확인할 수 있다.

MongoDB 데이터베이스의 생성은 MongoDB Atalas를 이용했는데, 이 블로그 글을 참고하였다.
MongoDB Atlas 평생 무료로 사용해보기
나만의 클라우드 Nosql 데이터 베이스 구축 해보기 오늘은 MongoDB Atlas을 활용해 보는 글을 작성해보겠습니다. NoSQL 란 NoSQL은 "Not Only SQL"의 약자로서, 기존의 관계형 데이터베이스와는 다른 형태의
it-creamstory.tistory.com
MongoClient를 사용해 MongoDB에 연결한다.
from pymongo import MongoClient
database_url = "..." # MongoDB 주소
# MongoDB 클라이언트 연결
client = MongoClient(database_url)
db = client["..."] # 데이터베이스 이름
collection = db["..."] # 컬렉션 이름
나는 복합키처럼 중복 삽입이 되지 않도록 할 부분에 고유 인덱스도 만들어주었다. (_id는 _id대로 생성)
# title과 artist 필드를 결합하여 고유 인덱스 생성
collection.create_index([("title", 1), ("artist", 1)], unique=True)
리스트 안의 필드들의 값이 모두 채워져있는 경우만,
중복된 데이터가 있을 경우 업데이트, 그렇지 않으면 삽입하도록 코드를 작성했다.
# 빈 문자열이 아닌 데이터만 MongoDB에 저장
for record in df.to_dict('records'):
# 빈 문자열이 아닌 필드만 포함된 데이터로 필터링
if all(record[field] != "" for field in ["title", "artist", "category"]):
collection.update_one(
{"title": record["title"], "artist": record["artist"]}, # title과 artist가 일치하는 데이터 찾기
{"$set": record}, # 일치하는 데이터가 있으면 업데이트
upsert=True # 데이터가 없으면 새로 삽입
)
print("데이터 저장 완료!")

데이터 저장이 완료되었다.
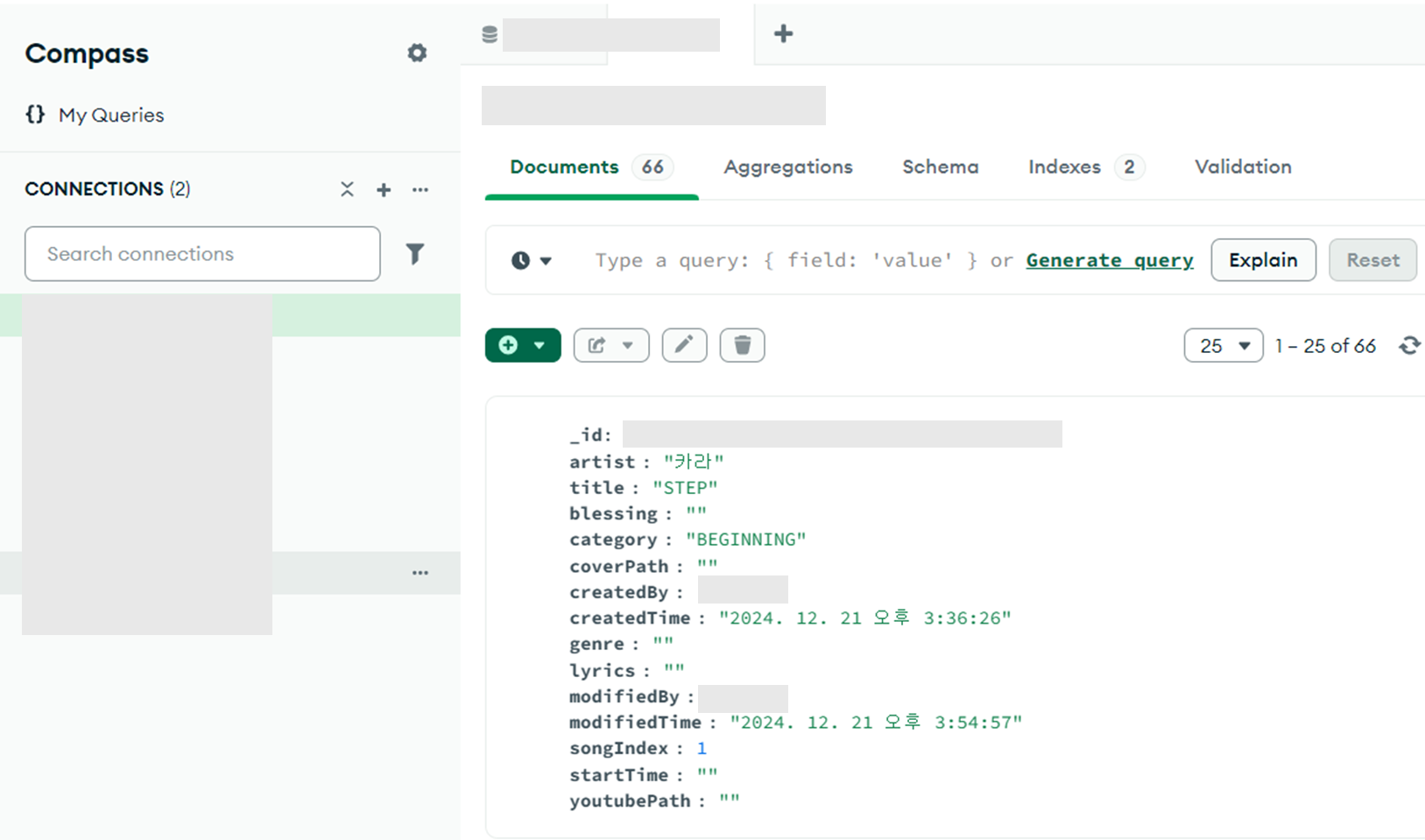
MongoDB Compass에 연결해서 데이터가 잘 삽입된 것을 확인하자.
+++
DB에 넣고 싶지 않은 필드는 제거해 주도록 수정했다.
# 'createdBy'와 'modifiedBy' 필드 제거 (DB에 삽입X)
df = df.drop(columns=["createdBy", "modifiedBy"], errors='ignore') # 'errors="ignore"'는 해당 열이 없을 경우 에러를 무시