
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |
- UNICON
- VPC
- 오블완
- 라피신
- UNICON2023
- 프로그래밍
- 인디게임
- EC2
- NAT gateway
- 체크인미팅
- 인프라
- 프리티어
- AWS
- 위키북스
- Route53
- CICD
- 티스토리챌린지
- 생활코딩
- 게임개발동아리
- 개발공부
- 백엔드개발자
- 스프링부트
- 42서울
- UNIDEV
- 온라인테스트
- 도커
- 전국대학생게임개발동아리연합회
- bastion host
- 자바개발자
- 백엔드
- Today
- Total
Hyun's Wonderwall
컴구 4단원 - The Processor (4.1, 4.2, 4.3 기본개념) 본문
4.1 Introduction
컴퓨터 성능을 결정하는 요인 3가지: 명령어 개수, 클럭 사이클 시간, 명령어당 클럭 사이클 수(CPI)
*명령어 개수: 컴파일러와 명령어 집합 구조가 결정함
*클럭 사이클 시간, CPI: 프로세서의 구현 방법에 따라 결정됨
이 장은 MIPS 명령어 집합을 두 가지 다른 방법으로 구현하여 데이터패스, 제어유닛을 만들고자 함.
프로세서를 구현하는데 사용되는 원리와 기법들 배움.
기본적인 MIPS 구현
구현할 MIPS 명령어 집합의 부분집합
- 메모리 참조 명령어: lw(load doubleword), sw(store doubleword)
- 산술/논리 명령어: add, sub, AND, OR, slt
- 조건부 분기 명령어: beq(branch equal), j(jump)
(이 부분집합은 정수 명령어를 다 포함하고 있는 것은 아니고 부동 소수점 명령어는 하나도 포함하지 않음.)
구현을 살펴보면서 (1) ISA가 구현의 여러가지 요소를 어떻게 결정하는지, (2) 여러가지 구현 젼략이 클럭 속도와 CPI에 어떻게 영향을 미치는지알아볼 것임. 이 장에서 MIPS 명령어의 일부를 구현하는데 사용되는 개념들은 다양한 종류의 컴퓨터를 만드는 데 쓰임.
구현에 대한 개요
어떤 명령어든지 처음 두 단계는 다음과 같이 동일함.
- 프로그램 카운터(PC)를 프로그램이 저장되어 있는 명령어 메모리에 보내어, 메모리로부터 명령어를 가져옴
- 읽을 레지스터를 선택하는 명령어 필드를 사용해 하나 또는 2개의 레지스터를 읽음.
워드 적재(lw) 명령어는 레지스터 하나만 읽지만 대부분의 다른 명령어는 레지스터 2개를 읽음.
이 두 단계 이후에 명령어 실행을 끝내기 위해 필요한 행동들은 명령어 종류에 따라 달라짐. (우리가 구현할 명령어들은 필요한 행동들이 대부분 같음)
점프 명령어를 제외한 모든 명령어는 레지스터를 읽은 후에 ALU를 사용함
- 메모리 참조 명령어: 주소 계산 위해 | 산술/논리 명령어: 연산 위해 | 분기 명령어: 비교 위해
ALU를 사용한 후에는, 명령어 종류에 따라 필요한 행동들이 서로 다름.)
- 메모리 참조 명령어: 메모리에 접근 (sw: 데이터 기록 위해, lw: 데이터 읽기 위해
- 산술/논리 명령어와 적재 명령어: ALU나 메모리에서 온 데이터를 레지스터에 써야 함
- 분기 명령어: 비교 결과에 따라서 다음 명령어의 주소를 바꿀 수도 있고, PC값을 4만큼 증가시켜서 다음 명령어의 주소를 갖도록 할 수도 있음
MIPS 구현을 위한 기능 유닛과 그들 사이의 연결을 보자.
멀티플렉서 소자(Mux): 제어선의 값에 따라 여러 개 입력 중에서 하나를 선택한이다. 데이터 선택기. 제어선은 주로 실행 중인 명령어에서 나오는 정보에 따라 설정된다. (명령어 종류에 따라 다르게 제어되어야 하는 유닛? - ex. 데이터 메모리는 lw일 때 읽기, sw일 때 쓰기. 레지스터 파일은 lw거나 산술/논리연산 명령어일 때만 쓰기.)

ALU는 여러 연산 중 하나를 수행해야 한다. 멀티플렉서처럼 ALU의 제어선도 명령어 필드 값에 따라 정해지며, 제어선이 연산을 통제한다.
데이터패스에 주요 기능 유닛을 위한 제어선과 필요한 멀티플렉서 3개를 추가한 그림
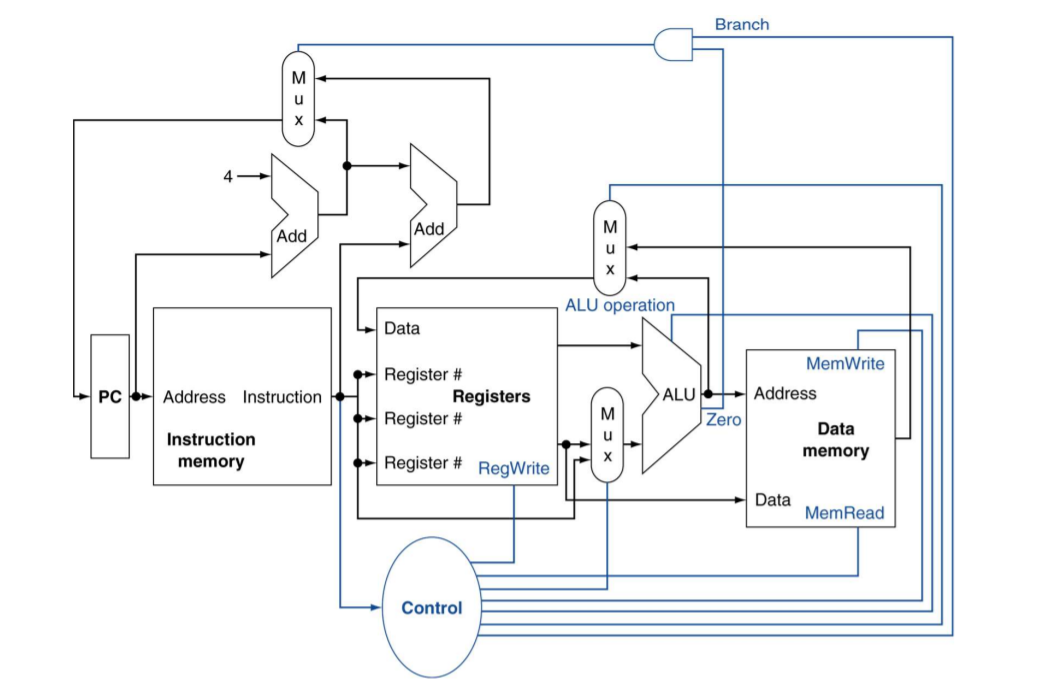
제어 유닛(Control unit): 명령어를 입력으로 받아서 유닛들과 두 멀티플렉서의 제어선 값을 결정한다.
세 번째 (제일 위의?) 멀티플렉서는 PC+4와 분기 목적지 주소 중 어느 것을 PC에 써야 할지 결정하는 것인데 ALU의 Zero 출력으로 제어된다. 이 출력의 값은 beq 명령어의 비교 결과로 결정된다. (분기하는 경우를 말하는 중)
// MIPS 부분잡합의 기본적 구현 설명
#4.1 MIPS 부분집합 구현의 추상적 개관. (주요 기능 유닛과 그들 사이의 연결)
1. 모든 명령어의 실행은 PC에 있는 명령어 주소를 명령어 메모리(Instruction Memory)로 보내는 것으로 시작된다.
2. 명령어를 가져온 후에는 명령어의 필드를 보고 명령어가 사용하는 레지스터 피연산자를 알아낸다.
레지스터 피연산자를 읽고, 메모리 주소를 계산하기 위해 (적재/저장) 또는 산술 연산 결과를 구하기 위해 (정수 산술/논리 명령어) 또는 비교하기 위해(분기) 피연산자에 대한 연산을 수행한다.
- 산술/논리 명령어이면 ALU 결과를 레지스터에 쓴다.
- 적재 명령어이면 ALU 결과를 주소로 사용하여 레지스터에 적재할 값을 쓴다.(읽는다)
- 저장 명령어이면 레지스터 값을 메모리에 저장한다.
- 분기 명령어의 경우는 ALU 풀력을 사용해 다음 명령어의 주소를 결정하는데, 이 주소는 오른쪽 덧셈기에서(PC에 분기 변위offset가 더해진 값) 나오거나 왼쪽 덧셈기에서(PC+4) 나온다.
기능 유닛들을 연결하는 굵은 선은 버스.(여러 개의 신호선들) 실제로는 그냥 연결할 수 없고 Mux 사용해야 한다.
#4.2 MIPS 부분집합의 기본적 구현. (필요한 멀티플렉서와 제어선을 포함)
- 맨 위의 멀티플렉서(Mux)는 어떤 값(PC+4 또는 분기 목적지 주소)이 새 PC값이 될지를 결정한다. 멀티플렉서 자체는 [ALU의 Zero 풀력과, 현재 명령어가 분기 명령어라는 것을 나타내는 제어선]을 AND하는 게이트에 의해 제어된다.
- 가운데 Mux는 ALU출력(산술/논리 명령어)와 데이터 메모리 출력(적재)중에서 어느 것을 레지스터 파일에 쓸 것인지를 결정하는 것으로, 그 출력이 레지스터 파일로 연결된다. -> 레지스터에 쓰게 됨
- 아래쪽의 Mux는 ALU의 두 번째 입력을 레지스터에서(산술/논리 또는 분기 명령어의 경우) 받을 것인지 아니면 명령어의 변위 필드(적재or저장)에서 받을 것인지를 결정하는 데 사용된다.
- 나머지 제어선들의 동작 - ALU가 수행할 연산을 결정하고, 데이터 메모리가 읽기를 할지 쓰기를 할지, 그리고 레지스터에 쓰기를 할지 말지를 결정한다.
MIPS 명령어 집합은 규칙적이고 단순해서 간단한 디코딩 과정만으로 제어선의 값을 결정할 수 있다.
더 구체화 -> 더 많은 기능 유닛을 추가하고 유닛간의 연결을 늘려야하며 제어유닛을 개선해서 각 명령어 종류에 대해 어떤 행동을 취할지 제어할 수 있도록 해야한다.
단순한 컴퓨터 제어 설계를 하는 동안 약간 긴 클럭 사이클을 쓸 것이다. 모든 명령어가 다 같은 클럭 사이클에 맞춰 실행 시작하는데(한 clock edge에서 실행을 시작, 다음 clock edge에 마침) 클럭 사이클이 가장 느린 명령어를 수용할 수 있을 만큼 길어야 하기 때문이다. 나중에 더 빠른 구현 알아볼 것임.
4.2 논리 설계 관례
정보는 0과 1로 인코딩됨 (low = 0, high = 1)
하나의 비트 표현마다 한 개의 선(wire)가 필요. 따라서 multi-bit 데이터는 multi-wite bus들로 인코딩됨
[ MIPS를 구현하는 데이터패스 요소 ]
두 가지 종류의 논리 소자: 조합 소자, 상태 소자
1. 조합 소자(Combinational element): 데이터 값에 대해 연산 수행.
- 출력이 현재 입력에 대해서만 결정된다. 같은 입력 주어지면 항상 같은 출력. output은 input의 function임.
(예시- AND-gate, adder, multiplexer, ALU) 내부 기억 장소 x
2. 상태 소자(Sequential, State Element): 상태를 갖는 것들. 정보를 저장. 소자에 내부 기억 장소 있.
(상태 소자는 현재값과 입력, clock 타이밍에 의해 output이 결정된다. 레지스터, 메모리 등에 사용.)
- 적어도 2개의 입력과 1개의 출력을 갖는다.
* 필수 입력: 기록할 데이터 값, 클럭(데이터 값을 상태 소자에 언제 쓸 것인지, 기록 시점 결정)
출력: 이전 클럭 사이클에 기록된 값.
(MIPS 구현에 쓰이는 상태 소자: 플립플롭, 레지스터, 메모리(명령어 메모리, 데이터 메모리)
상태 소자의 값을 읽는 것은 언제라도 가능하다.
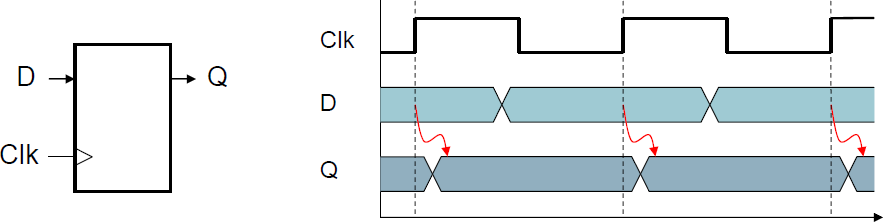
- 레지스터: 데이터를 회로에 저장.
(clock signal을 사용해 언제 저장된 값이 업데이트 되는지 결정. Edge-Triggered: clock이 0->1로 변할 때 (rising edge) 업데이트. 근데 정하기 나름, 여튼 edge)
- write control을 갖는 레지스터: only updates on clock edge when write control input is 1. stored value가 다음에도 쓰일 때 사용된다.
순차 회로(sequential circuit): 상태를 포함하는 논리 구성 요소들.
이들의 출력은 입력뿐만 아니라 내부 상태에 따라서도 달라진다. 예를 들면 레지스터 파일의 출력은 입력되는 레지스터 번호와 전에 레지스터에 기록된 값 모두에 영향을 받는다.
Clocking Methodology 클러킹 방법론
- 클럭을 기준으로 해서 데이터가 언제 유효한 값을 가지고 언제 안정되는지를 결정하는데 사용되는 방법. 신호를 읽고 쓰는 시점을 명확하게 지정한다.
- 에지 구동 클러킹: 모든 상태 변화가 클럭 에지에서 일어나는 클러킹 방법. (순차 소자의 값 변경이 상태 소자에서만 가능)
제어 신호: 멀티플렉서의 입력을 선택하거나 기능 유닛의 연산을 지시하기 위해 사용되는 신호. 기능 유닛이 연산에 사용할 정보를 가지고 있는 데이터 신호와 대비된다.

- 조합 논리 회로(Combinational logic)은 clock cycle동안 데이터를 변형한다.
ㆍclock edge 사이에. state element1->조합회로->state element2
ㆍ상태 소자들로부터 input이 되고, output 또한 상태 소자로 된다. (상태 소자들만이 데이터 값을 저장할 수 있기 때문)
- 신호가 상태 소자 2에 필요하는데 필요한 시간이 클럭 사이클의 길이를 결정하게 된다.
ㆍ가장 지연이 긴 시간(longest delay, 가장 느린 logic)이 클럭 주기를 결정한다.
참고: https://ydeer.tistory.com/143 [현록의 기록저장소:티스토리]
매 클럭 에지마다 상태 소자에 쓰기가 행해지는 경우는 쓰기 제어 신호를 안 쓰겠다 (always이므로)
그러나 상태 소자가 매 클럭마다 갱신되는 것이 아니라면 쓰기 제어 신호가 분명하게 표시되어야 한다. 클럭 신호와 쓰기 제어 신호는 상태 소자의 입력이며, 쓰기 제어 신호가 인가되고 활성화 클럭 에지일 때만 상태 소자가 변하게 된다.
*인가되다(asserted): 논리적으로 높은 신호, 참
에지 구동 방법론은 레지스터 내용을 읽고 그 값을 조합 회로로 보내고 같은 레지스터에 쓰는 작업 모두가 한 클럭 사이클에 일어나는 것을 허용한다. 조합 회로에 대한 입력은 선택된 클럭 에지(상향/하향 중 하나-이 책에서는 상향)에서만 변하기 때문. 한 클럭 사이클 내에서는 피드백이 되지 않는다.
32bit MIPS이므로 거의 모든 데이터가 32bit 폭을 가지고, 이 프로세서의 상태 소자와 논리 소자의 입출력 폭은 거의 다 32bit다.
버스(bus): 폭이 2bit 이상인 신호들(여러개의 신호들) 버스는 합쳐서 더 넓어질 수 있으며, 그럴 경우에는 버스 선에 레이블을 붙여 더 넓은 버스를 만들기 위해 버스들을 합쳤다는 것을 명확하게 나타낸다. 소자 간의 데이터 흐름 방향을 명확히 하기 위해 화살표를 붙이기도 한다.
데이터 운반 신호: 검은색, 제어 신호: 파란색.
4.3 데이터패스 만들기
Datapath: 데이터가 흐르는 경로. 연산을 위한 데이터든 그 결과든 흘러서 어디론가 전달되거나 저장되거나 한다. CPU에서 프로세스 데이터와 주소들의 요소가 전달되는 길.
데이터패스 구성 요소(datapath element): 프로세서 안에서 데이터를 연산하거나 저장하는 기능 유닛들.
- (명령어 메모리, 데이터 메모리, 레지스터 파일, ALU, mux, 덧셈기 등)
명령어별로 필요로 하는 데이터패스 구성 요소가 다르다. 추상화의 최상위 단계. 제어 신호도 같이 보자.
우리는 MIPS datapath를 순차적으로 만들어 볼 것임~
Instruction Fetch
첫 단계. 프로그램의 명령어를 저장하고 있다가 주소가 주어지면 명령어를 읽어서 보내주는 메모리 유닛.
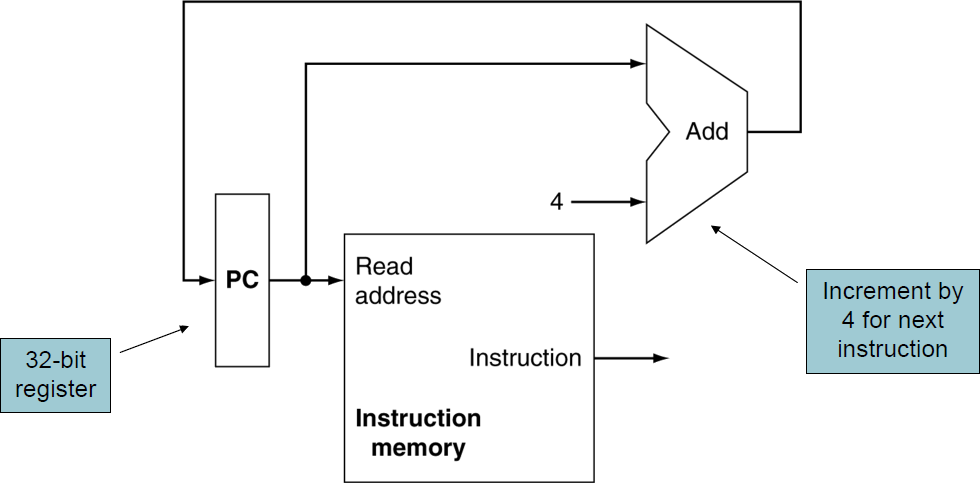
프로그램 카운터(PC): 현재 명령어의 주소를 가지고 있는 레지스터
PC를 다음 명령어 주소로 증가시키는 Adder가 필요 - ALU로 만듬. 항상 덧셈을 하도록 제어선을 고정시킴. 영구히 뎃셈기로 만들어져서 다른 기능은 수행할 수 없으므로 Add라는 레이블을 붙이도록 한다.
메모리에서 명령어 가져옴-> 다음 명령어 실행 준비를 위해 PC가 다음 명령어 가리키도록 4만큼 증가 -> 다음 명령어의 주소를 구하는 데이터패스를 만드는지를 확인
<각 명령어 종류에 필요한 데이터 패스 구성요소 알아보는 과정>
R형식 명령어
- 2개의 레지스터를 읽고 레지스터 내용에 ALU 연산 수행한 후 그 결과를 1개의 레지스터에 쓴다.
- 산술/논리 연산 수행 (add, sub, AND, OR, slt 명령어를 포함)
- 레지스터 그림 -
RegWrite / ALU 그림 - ALU Operation, Zero, ALU result 이런거 있는데 보기 (아래에서 래결됨)
- 5\ 4\ 같은거는 몇비트짜리인지를 나타낸 거임. 버스 참고 (일반적으로 32bit)
프로세서의 범용 레지스터 32개는 레지스터 파일이라고 하는 구조 속에 들어있다.
레지스터 파일은 접근할 때 레지스터 번호를 지정함으로써 읽고 쓸 수 있는, 레지스터들의 집합으로 구성된 상태 소자이다. 레지스터 파일은 컴퓨터의 레지스터 상태를 갖고 있다.
파일 내의 레지스터 번호를 지정하면 어느 레지스터라도 읽고 쓸 수 있다. 레지스터에서 읽어 들인 값들을 연산하려면 ALU가 필요하다.
R형식 명령어들은 레지스터 3개가 필요->레지스터 파일에서 데이터 워드 2개 읽고 데이터 워드 1개 써야 함.
레지스터에서 데이터 워드를 읽기: 레지스터의 입력과 출력이 하나씩 필요 (입력: 읽을 레지스터 번호를 지정, 출력: 레지스터에서 읽은 값 내보내기)
레지스터에서 데이터 워드를 쓰기: 레지스터의 입력이 2번 필요 (입력: 쓸 레지스터 번호를 지정, 입력: 레지스터에 쓸 데이터 값을 제공)
레지스터 파일은 Read Register 입력에 실리는 번호에 해당하는 레지스터의 "내용"을 항상 출력한다.
그러나, 쓰기는 쓰기 제어 신호에 의해 제어되므로(RegWrite가 제어선임!) 클럭 에지에서 쓰기가 일어나려면 이 제어 신호가 인가되어야 함. 따라서 전체적으로 4개의 입력(레지스터 번호 3개, 데이터 1개)과 2개의 출력(모두 데이터)가 필여힘.
레지스터 번호 입력은 5bit, 데이터 입력과 출력 버스는 모두 32bit 폭
읽을 레지스터 번호를 지정하는 입력과 레지스터에서 읽은 값을 내보내는 출력이다.
ALU는 32bit 입력 2개를 받아서 32bit 결과와, 결과가 0인지 아닌지를 나타내는 1비트 신호를 만든다. 그것이 바로 Zero인 것이다.
Load/Store Instructions 워드 적재 명령어, 워드 저장 명령어
- lw/sw $t1, offset_value($t2) 와 같은 형식.
- 베이스 레지스터와 16비트 부호있는 변위 필드를 더하여 메모리 주소를 계산.
- sw이면 $t1에 있는 저장할 값을 레지스터 파일에서 읽어 와야 한다. lw이면 메모리에서 읽어 들인 값을 $t1에 써야 한다.
- 두 경우 다 레지스터 파일과 ALU 필요.
- 16비트 변위 필드 값을 32비트 부호있는 값으로 부호확장하기 위한 유닛이 필요.
- 데이터 메모리는 읽기, 쓰기, 주소 입력, 메모리에 쓸 데이터 입력이 필요.
Read register operands 레지스터 피연산자를 읽는다. Calculate address using 16-bit offset 16비트 부호있는 변위 필드를 이용해 주소를 계산한다. (use ALU, but sign-extend offset 부호확장)
load: read memory and update register
store: write register value to memory
Data memory unit을 보면 - 제어선 MemWrite, MemRead있음. Address와 Write data가 입력이고 Read data가 출력임.
Sign extension unit을 보면 16bit가 들어와서 32bit가 나감.
Branch Instructions
-Read register operands 레지스터 피연산자를 읽는다. Compare operands (use ALU, subtract and check Zero output) 피연산자를 ALU 로 비교하여 차가 0인지 확인한다. Calculate target address - sign-extend displacement, shift left 2 places(word displacement), add to PC+4(Already calculated by instruction fetch)
-beq명령어는 비교할 레지스터 2개와 16비트 변위의 세 피연산자를 갖는다. 변위는 분기 목적지 주소(branch target address)를 분기 명령어 주소에 대한 상대적인 값으로 표현하는데 사용된다. 명령어 형태는 beq $t1, $t2, offset이다.
분기 목적지 주소 계산: PC+4+offset*4 (부호확장)
beq는 두 피연산자 값이 같으면 조건이 사실이 되어 분기한다. 분기 목적지 주소가 새로운 PC값이 된다. 그렇지 않으면 증가된 PC값이 새 PC값.
분기 데이터패스는 분기 목적지 주소를 계산하고 레지스터 내용을 비교하는 두 가지 일을 해야 한다.
분기 목적지 주소를 계산하기 위해서 분기 데이터패스에는 부호확장유닛, 덧셈기 있. 레지스터 사용하므로 레지스터파일, ALU도 필요. ALU의 Zero 신호는 항상 나타나지만 우리는 분기 명령어에서만 쓸것임.
jump명령어는 하위 26비트를 사용해 총 28비트범위 이동가능하다.
데이터패스 구축
그림으로 이해하였음
멀티플렉서, 제어유닛
그림~
'Subjects > 컴퓨터구조' 카테고리의 다른 글
| 컴퓨터구조 문제유형 (4단원) (0) | 2023.12.11 |
|---|---|
| 컴퓨터구조 4단원 - 4.4 단순한 구현, 4.6 파이프라이닝 (0) | 2023.12.05 |
