
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | ||||
| 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| 11 | 12 | 13 | 14 | 15 | 16 | 17 |
| 18 | 19 | 20 | 21 | 22 | 23 | 24 |
| 25 | 26 | 27 | 28 | 29 | 30 | 31 |
- openAI API
- bastion host
- CICD
- 게임개발동아리
- 생활코딩
- UNICON
- UNIDEV
- 체크인미팅
- 백엔드개발자
- 전국대학생게임개발동아리연합회
- Spring boot
- 스프링부트
- NAT gateway
- Route53
- Redis
- EC2
- springai
- 프롬프트엔지니어링
- UNICON2023
- 도커
- 캡스톤디자인프로젝트
- AWS
- 개발공부
- 프로그래밍
- 티스토리챌린지
- 오블완
- 인프라
- 라피신
- 프리티어
- 42서울
- Today
- Total
Hyun's Wonderwall
컴퓨터구조 4단원 - 4.4 단순한 구현, 4.6 파이프라이닝 본문
4.4 A Simple Implementation Scheme 단순한 구현
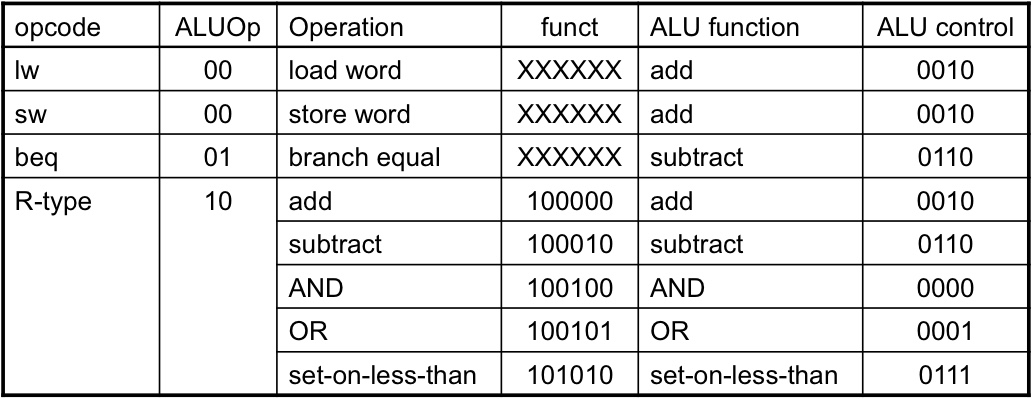
ALU 제어
ALU 제어선 - 기능
0000 - AND | 0001 - OR | 0010 - add | 0110 - sub | 0111 - slt | 1100 - NOR
명령어 종류에 따라 ALU의 수행 기능:
*Load/Store: add (주소계산)
*Branch: sub (레지스터값 서로 뺌)
*R-type: 명령어 하위 6비트 funct 필드에 의해 결정
2-bit의 ALUOp (opcode에서 파생됨), ALU control (조합논리에서 파생됨)
ALUOp: 적재/저장이면 00, 분기면 01, R-type이면 10. (입력값 11을 사용하지 않는다.)
ALUOp가 00이나 01이면 funct 필드가 don' t care이다.(XXXXXX)
ALUOp가 10이면 funct 필드 값이 ALU control을 결정하는데 쓰인다. 그리고 funct 맨앞 항상 10이다.
주 제어 유닛이 ALUOp비트를 생성, ALU 제어 유닛은 이것을 입력으로 받아 ALU를 제어하는 실제 신호를 만들어내는걸 다단계해독이라함. 다단계 제어 사용 -> 주 제어 유닛 크기 감소 -> 제어 유닛 속도 증가
# 2비트 ALUOp필드, 6비트 funct필드, 4비트의 ALU 연산 제어 비트 진리표
진리표가 만들어지면 이를 최적화하고 그다음에 게이트로 바꾼다.
주 제어 유닛의 설계 The Main Control Unit
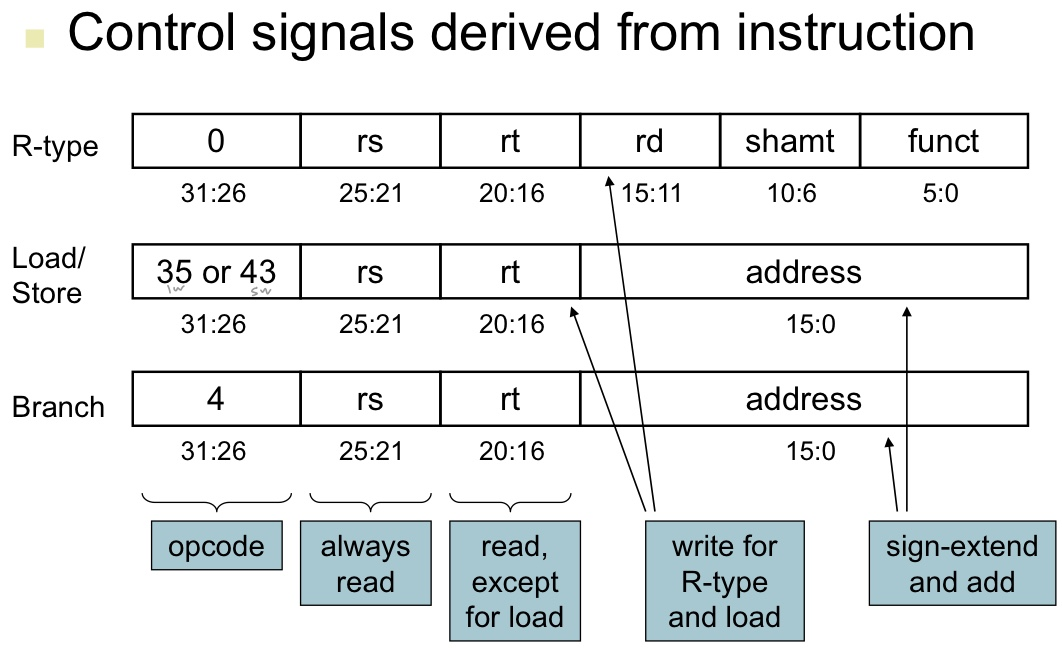
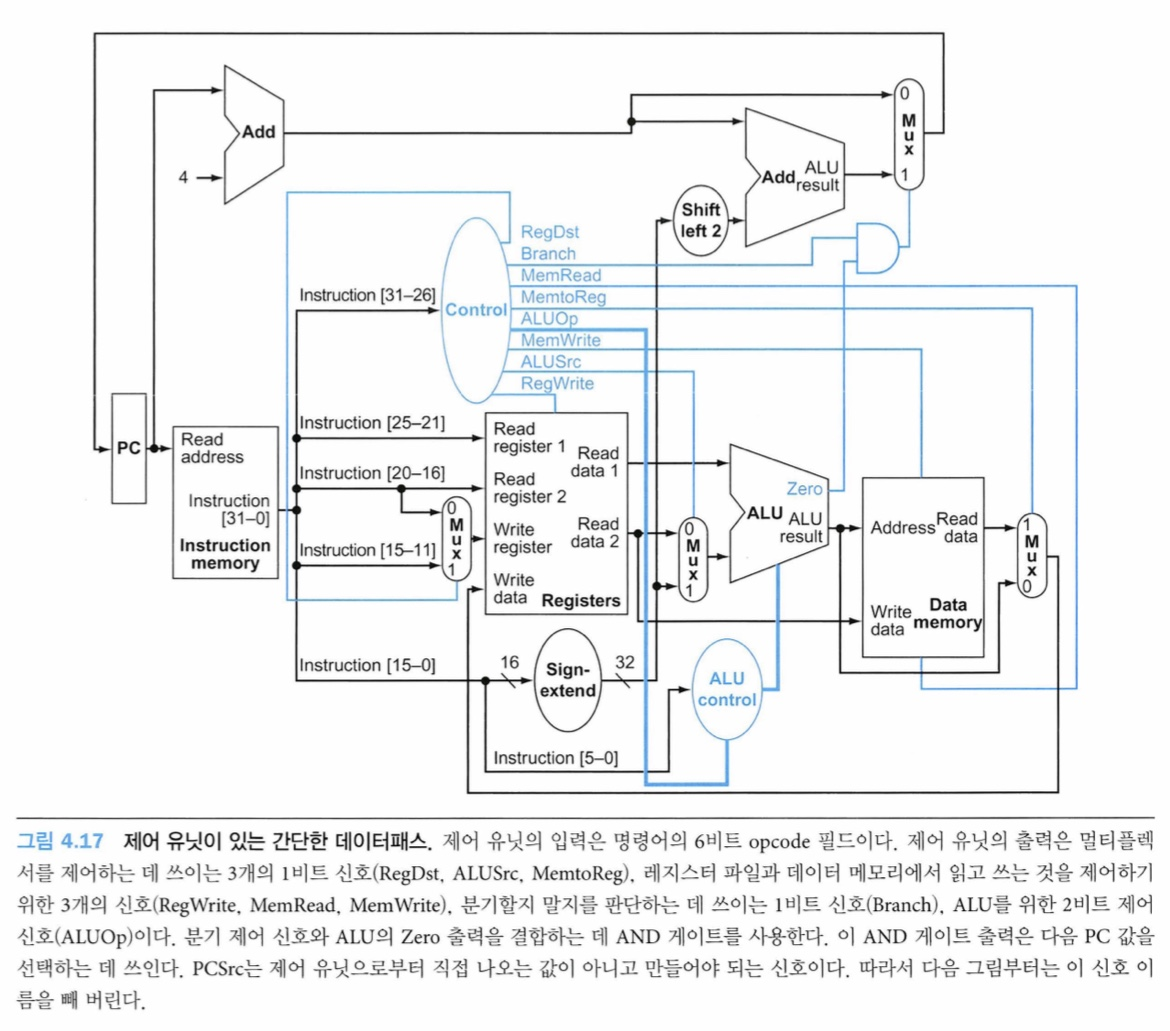
명령어 필드와 데이터패스에 필요한 제어선들 알아보자
세가지 종류 명령어 형식 다시 볼 떄 눈여겨볼 점이 있다
- opcode라 불리는 op필드는 항상 비트 31:26에 들어있다. 앞으로는 이 필드를 Op[5:0]이라고 부를 것임
- 읽을 레지스터 2개는 항상 rs[25:21], rt[20:16] 필드에 의해 지정됨. (R형식, beq, sw)
- 적재 명령어와 저장 명령어를 위한 베이스 레지스터는 항상 25:21(rs)에 있음.
- beq, 적재, 저장 명령어를 위한 16비트 변위는 항상 15:0에 있음.
- 목적지 레지스터는: 적재에서는 rt[20:16]에 있고 R형식에서는 rd[15:11]에 있다.
- -> 따라서 쓰기가 행해질 레지스터 번호로 명령어의 어느 필드를 쓸지 사용하기 위해서 멀티플렉서를 추가해야한다.
위의 정보를 이용하여 단순한 데이터패스에 명령어 레이블과 또 다른 멀티플렉서(레지스터 파일의 Write Register 번호 입력을 위해)를 추가한다. 그림을 보면 ALU 제어 블록, 상태 소자용 쓰기 신호, 데이터 메모리용 읽기 신호, 멀티플렉서용 제어 신호가 나타나 있다. 모든 멀티플렉서는 입력이 2개이므로 멀티플렉서 제어선은 1비트면 된다.
이 7가지 제어 신호 외워야 함
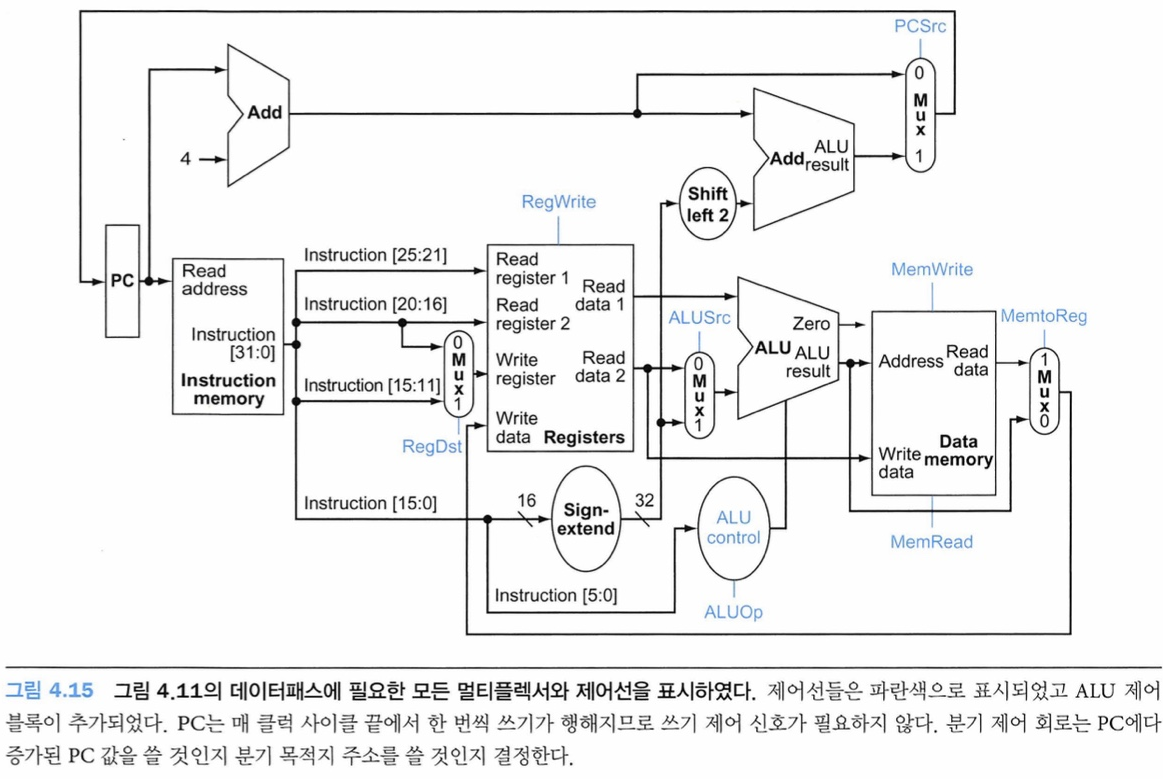
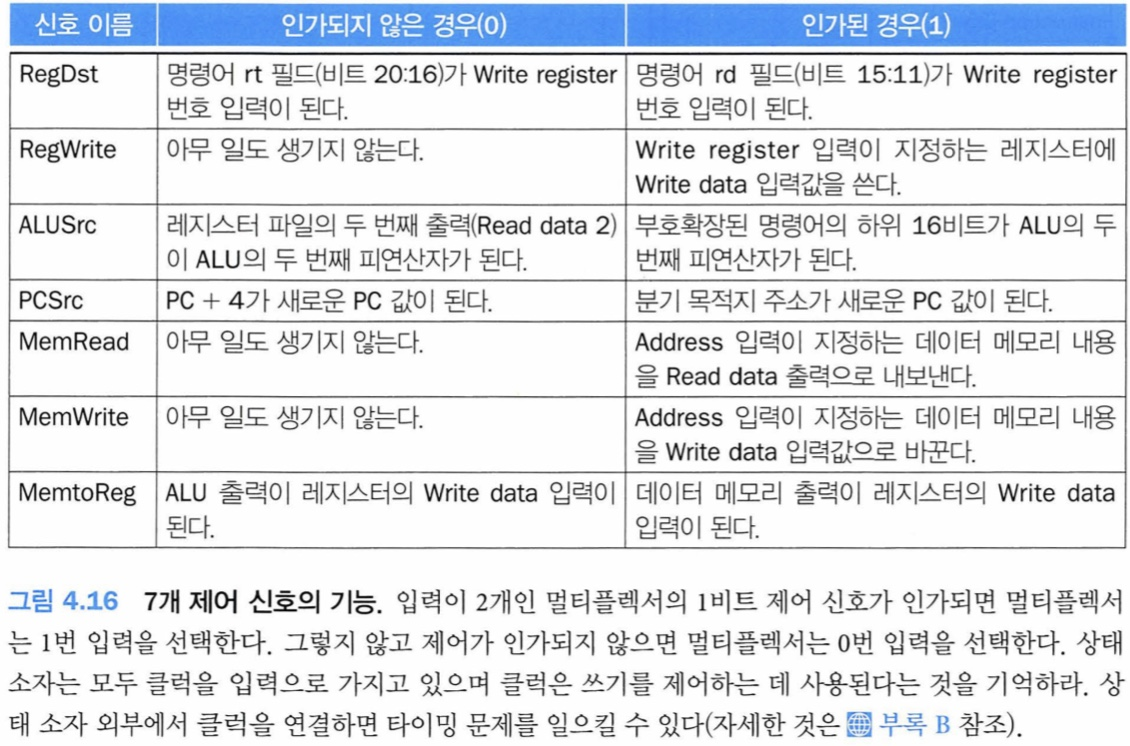
Datapath with Control 구조 그리면서 외우기
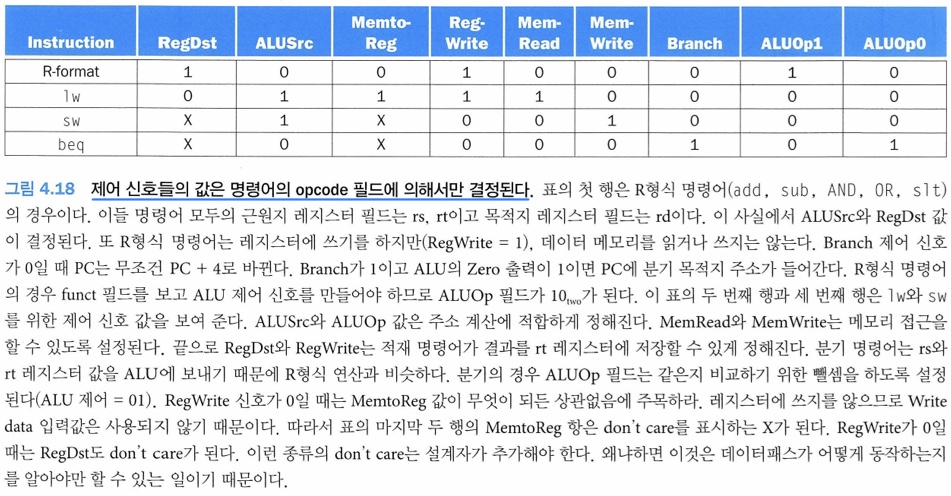
제어 신호들의 값은 명령어의 opcode 필드에 의해서만 결정된다. (명령어 유형에 따라 써야 하는 유닛이 다르므로)
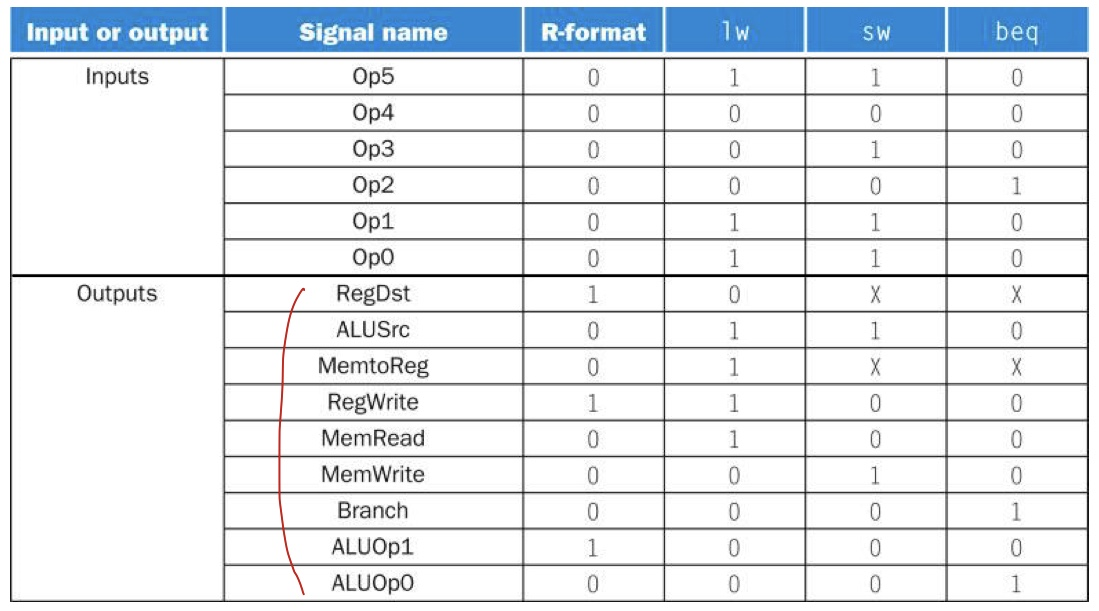
나중에 읽어보려고 캡쳐
그래서 R타입, lw, sw, beq가 다 쓰는 경로가 다르다. 그려보기!! 304p...
IF-ID-ALU 이런거 필기가 요기있네...
제어 유닛의 완성
제어 유닛 - 입력: opcode(6bit), 출력: 제어선들
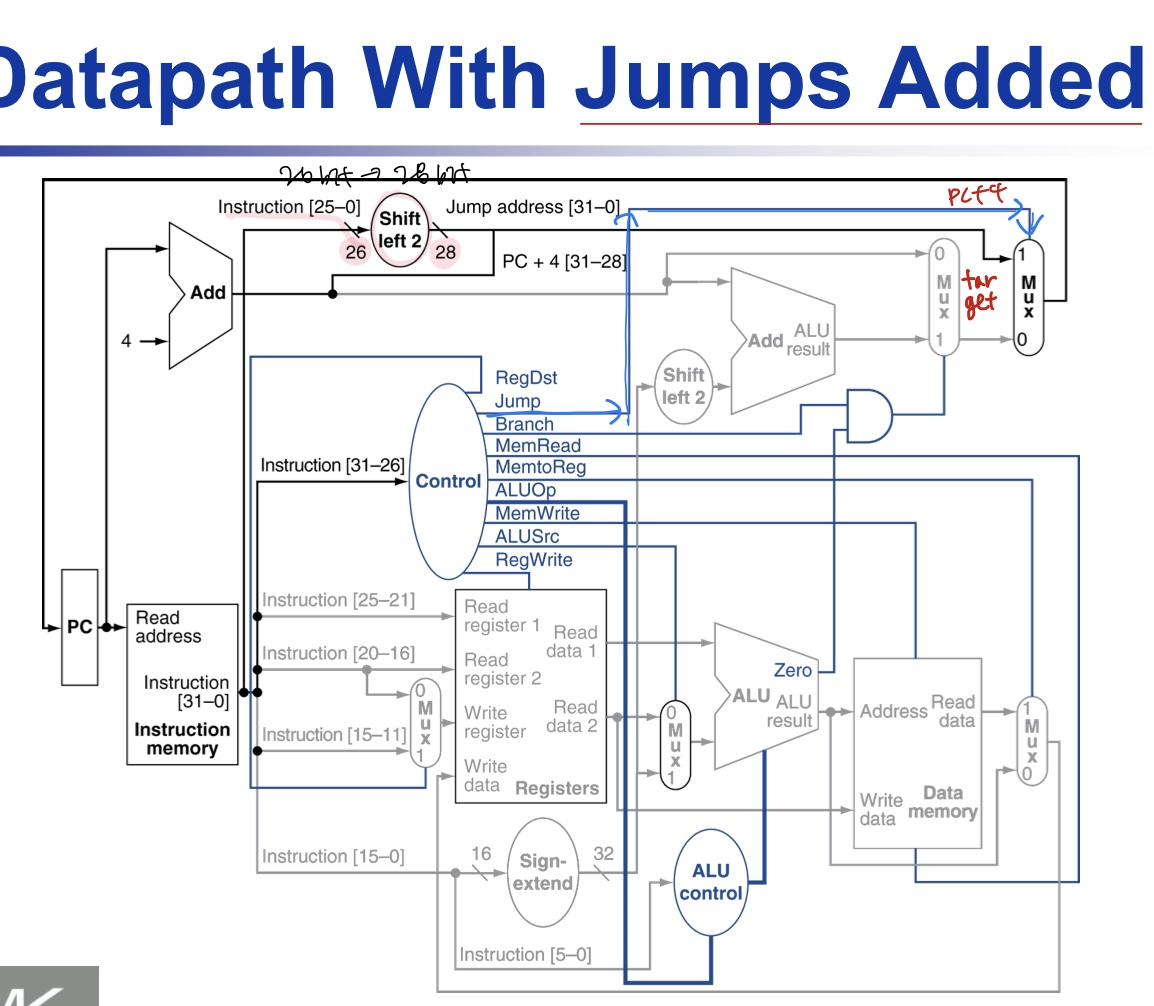
단일 사이클 구현(single-cycle implementation)을 거의 완성하였으니, 점프 명령어를 추가
점프 명령어의 구현
점프 명령어 특징: 무조건 분기
PC를 다음 값의 concatenation으로 update:
[4bit] PC+4의 상위 4비트, [26bit] 26비트 주소 필드, [2bit] 00
opcode: 2 -> 추가 제어 신호 필요
이제 PC값을 선택할 때 PC+4, 분기 목적지 PC, 점프 목적지 PC 중 하나를 새로운 PC 값의 근원지로 선택해야 함 (Mux 추가) - 제어 신호 'Jump': opcode가 2일 때만 인가된다.
Performance Issues
단일 사이클 구현은 오늘날 왜 사용되지 않는가?
클럭 사이클이 모든 명령어에 대해 같은 길이를 가져야 함. 클럭 사이클은 컴퓨터에서 가능한 경로 중 가장 긴 경로에 의해 결정됨. 적재 명령어: 명령어 메모리->레지스터 파일->ALU->데이터 메모리->레지스터 파일... CPI 값은 1이지만, 클럭 사이클이 너무 길어서 전체 성능이 좋지 않음.
(4.5은 없음)
파이프라이닝 구현기술 살펴보자. 유사한 데이터패스 사용하나 여러개의 명령어를 동시에 실행해 효율높임
4.6 Pipelining Analogy
Pipelined Laundry: overlapping execution 병렬적 수행이 성능을 향상한다.
파이프라이닝은 시스템의 명령어 처리량을 증가시킴 -> 전체 시간 단축되는 성능 향상 (개별 실행시간은 단축X)
[MIPS Pipeline - 5단계]
1. IF: Instruction fetch from memory (메모리에서 명령어를 가져온다)
2. ID: Instruction decode & register read (명령어를 해독하는 동시에 레지스터를 읽는다)
3. EX: Execute operation or calculate address (연산 수행 or 주소 계산)
4. MEM: Access memory operand (데이터 메모리에 있는 피연산자에 접근)
5. WB: Write result back to register (결과값을 레지스터에 쓴다)
4.5에서는 lw, sw, add, sub, AND, OR, slt, beq 8개 명령어를 생각하겠다
파이프라인 구현에서도 모든 단계가 한 클럭 사이클에 처리된다. 그래서 마찬가지로 클럭 사이클이 충분히 길어야 한다.
성능 향상: 명령어 사이의 시간(파이프라인) / 명령어 사이의 시간(파이프되지x) = 파이프 단계 수 {이상적인 상황에서, 실제로는 더 작아짐}
이상적인 조건하에서 매우 많은 명령어를 실행하는 경우, 파이프라이닝에 의한 속도 향상은 파이프 단계 수와 거의 같다.
그러나 단계들이 보통 완벽하게 균형잡혀있지 않으며, 파이프라인은 어느정도의 오버헤드를 유발한다.
so 파이프라이닝에서 명령어당 시간이 가능한 최소값보다 커져서 속도 향상은 파이프라이닝 단계수보다 작아진다.
파이프라이닝을 위한 명령어 집합 설계
MIPS 설계가 의도된 거였다 이말이야
1. 모든 MIPS 명령어 32bit 같은 길이
2. 명령어 형식이 적고 규칙적
3. 메모리 접근을 적재, 저장 명령어로만
4. 메모리 피연산자의 정렬 - 메모리 접근 한 사이클만에 가능
파이프라인 해저드
해저드(hazard): 다음 명령어가 다음 클럭 사이클에 실행될 수 없는 상황. 3종류가 있다
구조적 해저드: 요구된 리소스가 바쁠 때. (리소스 사용 겹침으로 인한 충돌.)
ex- If 파이프라이닝이 싱글 메모리였다면...
파이프라인에서 1, 2, 3번째 명령어 진행한 상태에서 4번째 명령어 수행시, 1번째 명령어가 메모리에서 데이터에 접근하고 4번째 명령어가 같은 메모리에서 명령어를 인출하게 된다. so 버블 필요, 클럭 사이클 낭비 (버블이란? 아무것도 수행하지 않고 시간을 버는 것.)
-> 따라서 파이프라인 데이터패스들은 분리된 instruction/data 메모리들 필요. 아니면 instruction/data cache를 분리해야.
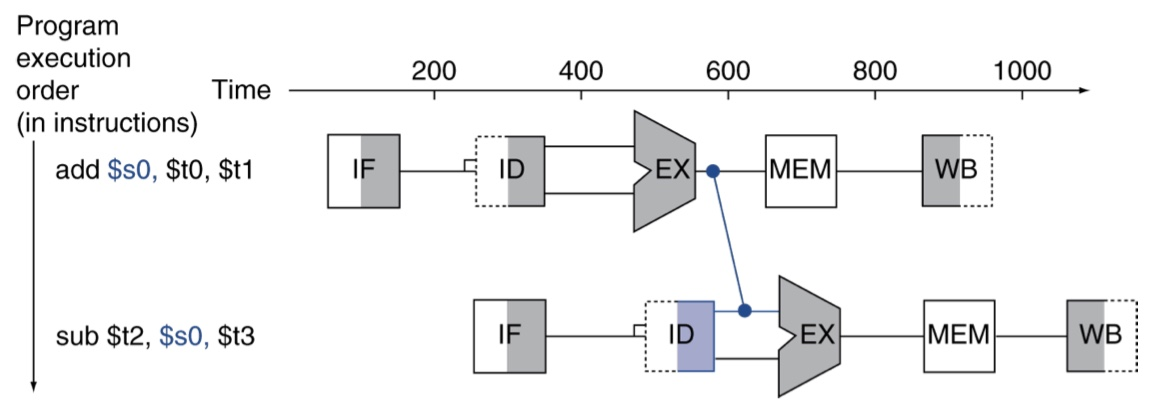
데이터 해저드: 이전 명령어의 데이터 읽기/쓰기가 완료되기를 기다려야 할 때. (어떤 명령어가 아직 파이프라인에 있는 앞선 명령어에 종속성을 가짐)
ex- 레지스터 연이어 사용해 계산해야 하는 경우. add 계산 후 값 불러와 sub 하려고 할 때, add에서 결과값을 쓸 때까지 기다려야 함. 버블 생김, 클럭 사이클 낭비
어떻게 해결? 전방전달 forwarding (aka bypassing)
결과를 계산되자마자 사용한다. 레지스터에 저장x. 데이터패스의 추가적인 연결들이 필요!
적재-사용 데이터 해저드 Load-Use Data Hazard: 항상 전방전달로 지연을 피할 수는 없다. load 명령어 다음에 R형식 명령어로 데이터 사용하려고 할 때 파이프라인 지연(버블) 만들어야.
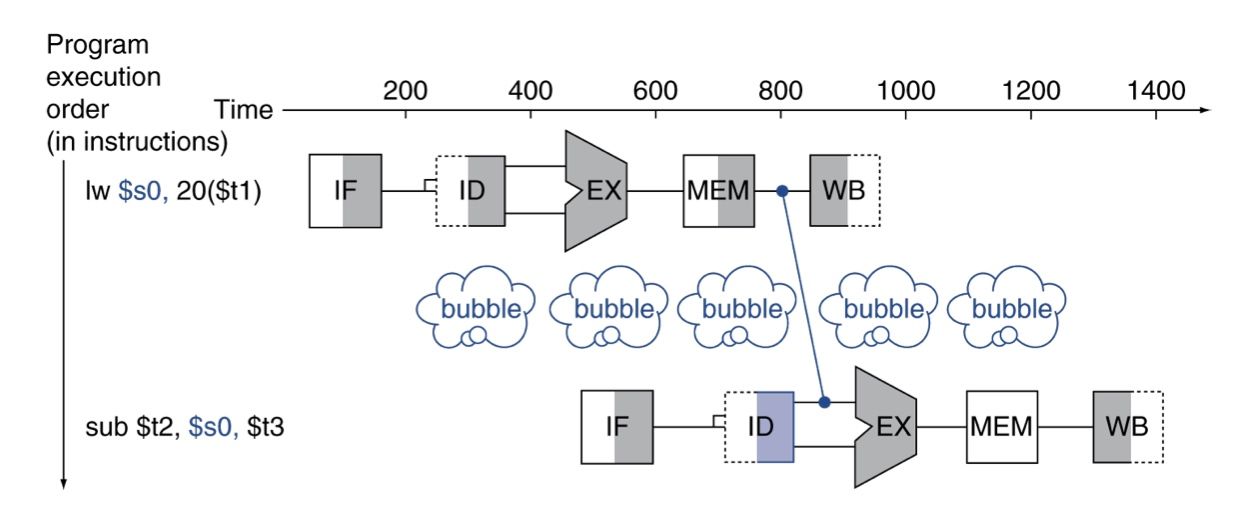
Code Scheduling to Avoid Stalls: 다음 명령어에서 load한 결과를 바로 쓰지 않도록 코드 순서 바꾸기!!
제어 헤저드: 조건부 분기 명령어 사용시 발생하는 해저드. 다음 명령어 무엇을 실행해야 하지?
Branch가 제어의 flow를 결정한다.
다음 명령어를 가져오는 것은 branch outcome에 의존한다. pipeline은 항상 옳은 명령을 가져오지 않을수도 있다. (still working on ID stage of branch)
따라서 파이프라인에서 레지스터들을 비교하고 target을 일찍 연산할 필요가 있다
add hardware to do it in ID stage
<첫 번째 방법>
분기 시 지연 Stall on Branch: 다음 명령어를 가져오기 전에 브랜치 결과가 결정되는 것을 기다림.
- beq를 쓰면 ALU에서 계산하고 Zero여부 나오므로 이때 IF. 한 클럭 사이클 지연 (버블)
Q. 분기 명령어가 나오면 무조건 지연시키는 방법이 CPI에 미치는 영향을 계산하라. (다른 모든 명령어의 CPI는 1)
- 분기 명령어가 SPECint2006에서 실행되는 명령어의 17%. 다른 명령어들은 CPI가 1이고, 분기 명령어는 지연 때문에 한 클럭 사이클이 더 필요하여 CPI가 2가 된다. 따라서 전체 CPI 값은 1.17, 이상적인 경우와 비교하면 1.17배 속도 저하.
- 성능에 좋지 않음.
<두 번째 방법>
분기 예측 Branch Prediction: 예측을 기본적으로 '분기하지 않는 것'으로 진행한다.
예측이 맞았다면 지연 없이 진행. / 예측이 틀렸다면 re-fetch하여 분기 진행, 지연 한 사이클.
더 정교한 분기 예측 More-Realistic Branch Prediction
Static branch prediction. 전형적인 분기 행동에 따라.
- backward 분기들은 taken(분기o), forward 분기들은 untaken(분기x)으로 예측
(backward 분기: 현재 주소보다 작은 주소로 점프=지나온 길로 즉 후방으로 점프=항상 일어난다고 예측. loop와 if.)
Dynamic branch prediction 동적 하드웨어 예측
- 하드웨어가 실제 개별 분기 명령어의 행동을 측정한다. (각 분기의 히스토리를 기록)
- 미래 행동도 trend를 따라갈 것이라고 가정한다. 예측이 틀렸다면, re-fetching 위해 지연되는 동안 히스토리를 업데이트.
파이프라인 요약
- 파이프라이닝은 명령어 처리량을 증가시킴으로써 성능을 향상시킨다. 여러 명령어들을 병렬적으로 실행, 각 명령어는 같은 지연시간(latency) 가진다.
- 해저드 종류(Structure, Data, Control) 잘 알기. 전방전달과 분기 예측.
- Instruction Set design은 파이프라이닝 적용의 복잡성에 영향을 미친다.
'Subjects > 컴퓨터구조' 카테고리의 다른 글
| 컴퓨터구조 문제유형 (4단원) (0) | 2023.12.11 |
|---|---|
| 컴구 4단원 - The Processor (4.1, 4.2, 4.3 기본개념) (0) | 2023.11.28 |
