
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | ||||
| 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| 11 | 12 | 13 | 14 | 15 | 16 | 17 |
| 18 | 19 | 20 | 21 | 22 | 23 | 24 |
| 25 | 26 | 27 | 28 | 29 | 30 | 31 |
- 프리티어
- 티스토리챌린지
- AWS
- 인프라
- NAT gateway
- 개발공부
- 라피신
- 스프링부트
- Redis
- 체크인미팅
- CICD
- 게임개발동아리
- UNICON
- 도커
- UNICON2023
- 프로그래밍
- Route53
- EC2
- 오블완
- bastion host
- 백엔드개발자
- Spring boot
- 42서울
- 생활코딩
- 전국대학생게임개발동아리연합회
- 캡스톤디자인프로젝트
- openAI API
- spring ai
- UNIDEV
- 프롬프트엔지니어링
- Today
- Total
Hyun's Wonderwall
[AIchemist] 파머완 - CH02. 사이킷런으로 시작하는 머신러닝 (6. 사이킷런으로 수행하는 타이타닉 생존자 예측) 본문
[AIchemist] 파머완 - CH02. 사이킷런으로 시작하는 머신러닝 (6. 사이킷런으로 수행하는 타이타닉 생존자 예측)
Hyun_! 2023. 9. 25. 17:45AIchemist 1기
- 이화여대 머신러닝 입문 스터디
- 스터디 교재: 권철민, "파이썬 머신러닝 완벽 가이드"
- 1주차 과제: 파머완 ~128p (챕터2 섹션5)
[CH1] 파이썬 기반의 머신러닝과 생태계 이해 ~ [CH2] 사이킷런으로 시작하는 머신러닝
AIchemist 1th Session(2023.9.23)
- [사이킷런으로 수행하는 타이타닉 생존자 예측] 실습 진행
- 먼저 한 일 : 캐글에서 타이타닉 탑승자 데이터 다운로드 (1장에서 판다스 DF 설명할 때 내려받음)
- 내려받은 탑승자 데이터에 있는 정보 : Passengerid, survived, pclass, sex, name, age, sibsp, parch, ticket, fare, cabin, embarked
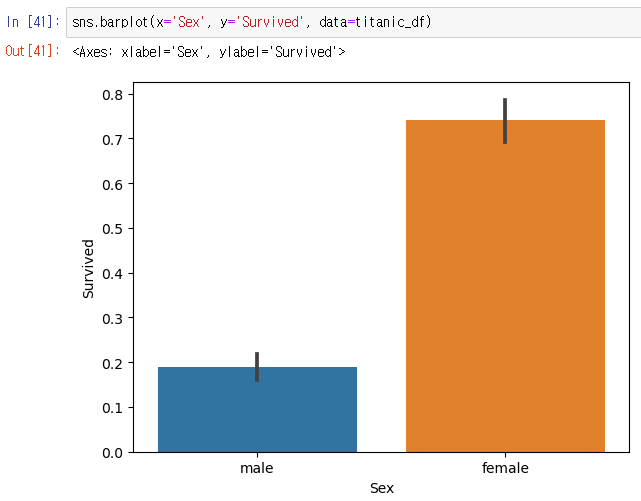
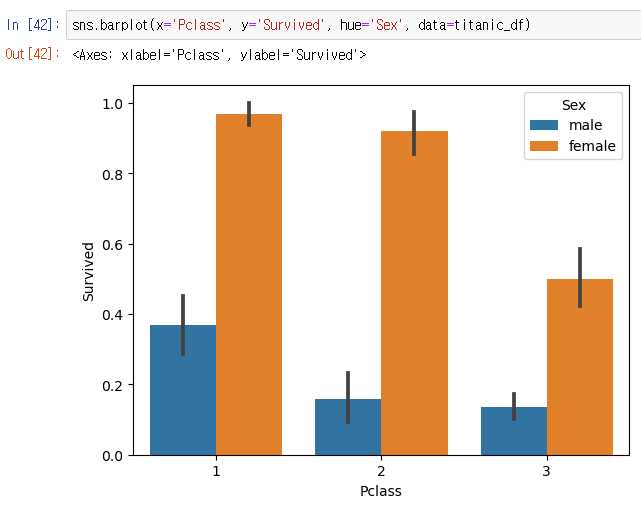
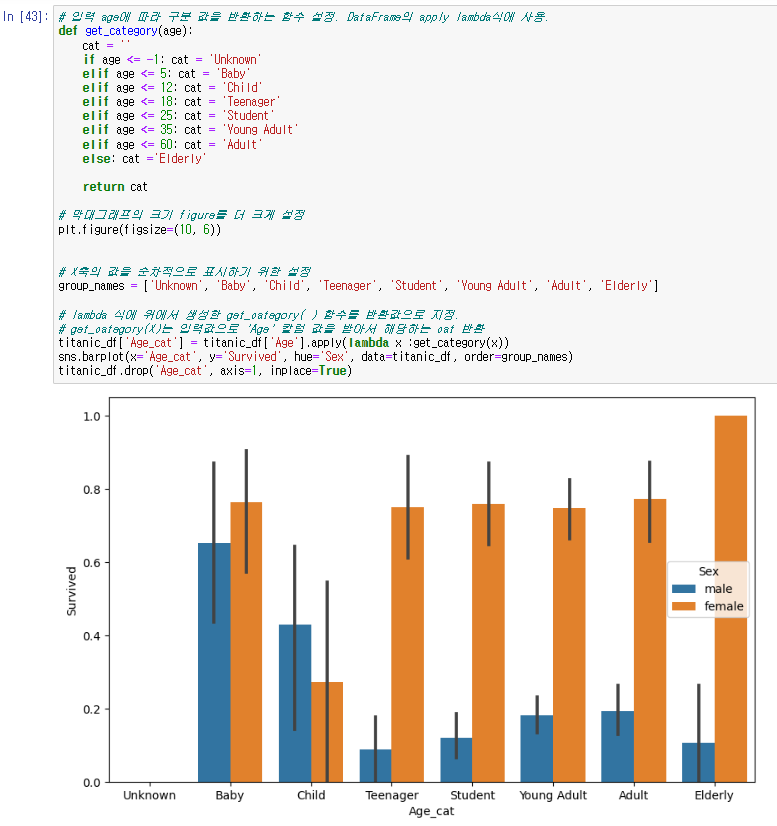
New! > 시각화 패키지-맷플롯립, 시본 이용해 차트 그래프 시각화 해보자.
(1) 주피터 노트북 생성, 분석에 필요한 라이브러리 임포트
(2) 타이타닉 탑승자 파일을 read_csv() 이용해 DataFrame으로 로딩 후 3개 row 데이터 출력함
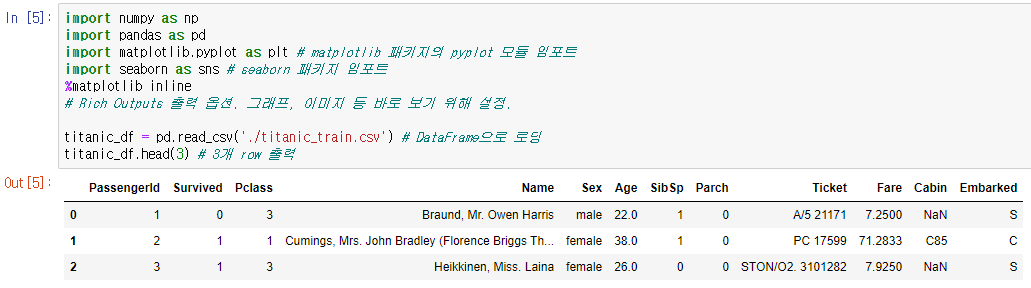
- matplotlib : 데이터 시각화 패키지. plt로 선언하는 것이 관례.
matplotlib에서 pyplot 모듈을 가져온다. - seaborn : 데이터 시각화 패키지. sns로 선언하는 것이 관례.
barplot()으로 막대그래프를 그릴 예정이다. - %matplotlib inline
-> Rich Outputs 출력 옵션으로 도표, 그래프, 이미지, 소리 애니메이션 등의 산출물들이 Jupyter Notebook을 실행한 브라우저에서 바로 볼 수 있게 해준다. (실행하면 결과가 셀 아래 inline으로 표시됨)
(궁금증 검색)
- 플로팅(plotting) : 데이터를 그래프로 그리는 것을 말한다. matplotlib, barplot 등에 plot이 붙어있는 이유!
- 라이브러리, 패키지, 모듈 차이
- 라이브러리: 여러 패키지와 모듈들을 모아놓은 것. 라이브러리는 패키지의 집합으로 패키지보다 포괄적인 개념이지만 자주 혼용해서 사용된다. (ex. 넘파이 패키지, 넘파이 라이브러리)
- 패키지: 특정 기능과 관련된 여러 모듈을 한 폴더 안에 넣어 관리하는 것. 일반 디렉토리가 아닌 패키지임을 인식하기 위해서는 각 폴더마다 __init__.py라는 파일을 생성해야 한다.
- 모듈: 함수, 변수, 클래스 등을 모아놓은 '.py' 확장자의 파일.
라이브러리>=패키지>모듈
○ 로딩된 데이터 칼럼 타입 확인 - DataFrame.info()
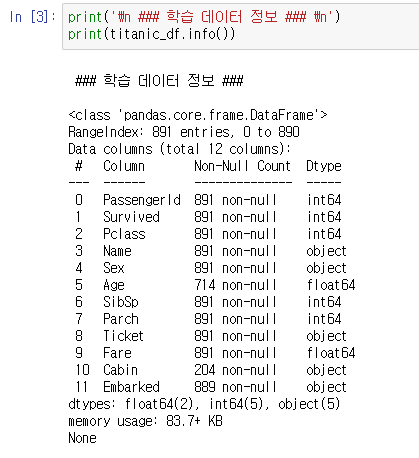
- RangeIndex : DF 인덱스의 범위 나타냄=전체 row 수
- Data columns : 전체 칼럼 수
- 아래로 칼럼들의 이름, Non-Null Count(Null이 아닌 데이터 갯수), Dtype 확인가능.
- dtypes : 칼럼의 데이터 타입 (float64 타입 칼럼이 2개, ...)
*이때 object 타입은 string 타입으로 봐도 무관. 넘파이의 String 타입이 길이 제한이 있어서 구분을 위해 object 타입으로 명기한 것)
○ Non-Null Count로부터 Null 값(NaN) 개수를 알 수 있음
사이킷런 머신러닝은 Null 값을 허용하지 않으므로 Null 값을 어떻게 처리할지 결정해야 함.
여기서는 DataFrame.fillna() 함수를 이용해 Null 값을 평균 또는 고정 값으로 변경.
- Age 칼럼은 평균 나이로, 나머지 칼럼은 'N' 값으로 변경, 그후 모든 칼럼의 Null 값이 없는지 재확인~
+ 주어진 코드에서 titanic_df.isnull().sum().sum() 하는데 sum()을 두 번 수행하는 이유는 DF가 2차원이라서. sum()을 1번만 쓰고 실행해보면 이유를 알 수 있음.
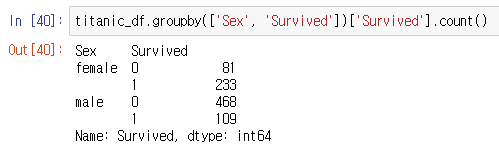
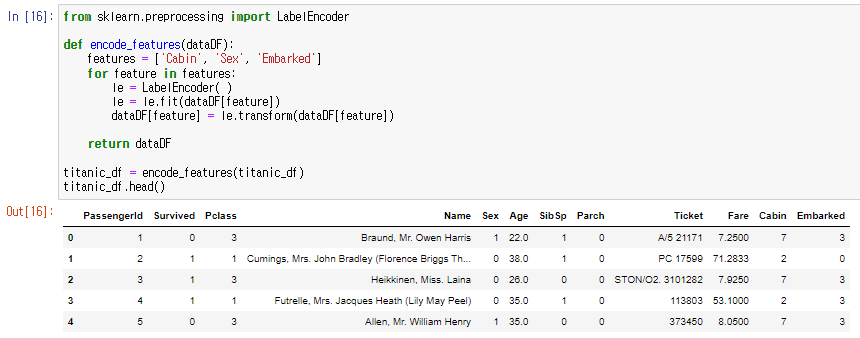
○ 문자열 피처들의 값 분류 살펴보기 : titanic_df['Cabin'].value_counts()
같은 방식으로 칼럼 지정해 .value_counts()
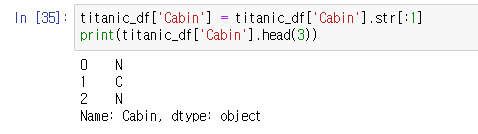
이때 Cabin 속성값 제대로 정리되어있지 x, Cabin 속성의 앞 문자만 추출하자. (ex. C11 C12 등을 C로 바꾸기)
titanic_df['Cabin'] = titanic_df['Cabin'] ....
'Study > Python-Machine-Learning' 카테고리의 다른 글
| [AIchemist] 파머완 - CH03. 평가 (6. 피마 인디언 당뇨병 예측) (0) | 2023.10.09 |
|---|---|
| [AIchemist] 파머완 - CH03. 평가 (1~5) (0) | 2023.09.26 |
| [AIchemist] 파머완 - CH02. 사이킷런으로 시작하는 머신러닝 (1~5) (0) | 2023.09.19 |
| [AIchemist] 파머완 - CH01. 파이썬 기반의 머신러닝과 생태계 이해 (4. 데이터 핸들링 - 판다스) (0) | 2023.09.19 |
| [AIchemist] 파머완 - CH01. 파이썬 기반의 머신러닝과 생태계 이해 (3. 넘파이) (0) | 2023.09.18 |
