
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |
- Route53
- UNICON2023
- 프로그래밍
- bastion host
- 개발공부
- 백엔드
- 자바개발자
- 티스토리챌린지
- UNICON
- 라피신
- 도커
- 백엔드개발자
- 인디게임
- 42서울
- NAT gateway
- 생활코딩
- UNIDEV
- 체크인미팅
- 프리티어
- AWS
- CICD
- 온라인테스트
- 스프링부트
- 인프라
- 전국대학생게임개발동아리연합회
- VPC
- EC2
- 오블완
- 위키북스
- 게임개발동아리
- Today
- Total
Hyun's Wonderwall
[데이터베이스] Chap 1. Introduction 본문
Chapter 1. Introduction
Outline:
- Database-System Applications
- Purpose of Database Systems
- View of Data
- Database Languages
- Database Design
- Database Architecture
- Database Users and Administrators
- History of Databaase Systems
Database Systems - 데이터베이스 (관리) 시스템
DBMS(Database Management System): 특정 기업에 대한 정보를 포함한다.
- Collection of interrelated data (상호 관련된 데이터들의 집합)
- Set of programs to access the data (DBMS는 데이터에 접근할 수 있는 프로그램들의 모음을 포함한다.)
- An environment that is both convenient and efficient to use. (사용자에게 편리하고 효율적인 환경을 제공)
데이터베이스 시스템은 다음과 같은 데이터 모음을 관리하는 데 사용된다.
- Highly valuable (가치가 높은)
- Relatively large (비교적 큰)
- Accessed by multiple users and applications, often at the same time (다양한 사용자들과 애플리케이션들로부터 액세스되는)
현대의 데이터베이스 시스템은 대규모의 복잡한 데이터 집합을 관리하는 것이 임무인 복잡한 소프트웨어 시스템이다.
데이터베이스는 우리 삶의 모든 측면에 영향을 끼친다.
Purpose of Database Systems
초창기에는 데이터베이스 애플리케이션이 파일 시스템 바로 위에 직접 구축되어 있었다.
File System에서 발생된 문제들: (=DB가 해결하는 것들)
- Data redundancy and inconsistency 데이터 중복 및 불일치
- data is stored in multiple file formats resulting in duplication of information in different files (데이터가 여러 파일 형식으로 저장되어서 여러 파일에 정보가 중복된다.)
- Difficulty is accessing data 데이터 액세스의 어려움
- Need to write a new program to carry out each new task (각각의 새로운 작업을 수행하기 위해 새 프로그램을 작성해야 한다.)
- Data isolation 데이터 고립
- Multiple files and formats (여러 파일 및 형식 -> 데이터 관리 복잡.)
- Integrity Problems 무결성 문제
- Integrity constraints become "buried" in program code rather than being stated explicity. (무결성 제약 조건을 프로그램 코드로 써서 명시되지 않고 코드에 묻혀 버린다.)
- Hard to add new constraints or change existing ones (새 조건을 추가하거나 기존 제약 조건을 변경하기 어렵다. 코드를 바꿔야 하므로...)
- Atomicity of updates 업데이트의 원자성(보장 못 함)
- Atomicity란? 원자성 - 쪼갤 수 없는 특성. 데이터들을 건드릴 때 다 같이 하나처럼 동작해야 한다. 트랜잭션과 관련.
- 장애가 발생하면 부분 업데이트만 수행되어 데이터베이스가 일관되지 않은 상태로 남을 수 있다. ex: 이체하는 것은 완료되거나 전혀 발생하지 않아야 한다. (트랜잭션은 commit / abort, 두 가지 선택지만 존재)
- Concurrent access by multiple users 여러 사용자의 동시 엑세스
- 성능을 위해 동시 엑세스가 필요하다.
- 제어되지 않는 동시 엑세스로 인해 불일치가 발생할 수 있다. (데이터 일관성 지켜야! 동시성 제어 필요.)
- Security Problems 보안 문제
- 파일에서는 데이터의 일부만 공유하는 것이 어렵다. DB에서는 view, sub table 기능을 사용할 수 있다.
Database systems은 위의 모든 문제에 대한 해결책을 제공한다.
File system 단점 = DB 장점, 목적! ★★★
1. 데이터 중복성, 일관성 보장
2. 데이터 접근 용이
3. 데이터 고립 방지
4. 무결성 문제 해결
5. Atomicity of Updates 업데이트의 원자성 보장
6. 다중 사용자, 동시 수행 잘 되도록 동시성 제어
7. 보안 문제 해결
View of Data
데이터베이스 시스템은 밀접한 관계의 데이터들과, 그러한 데이터에 액세스하고 수정할 수 있게 하는 프로그램들의 모임이다. 데이터베이스 시스템의 주 목적은 사용자에게 데이터의 abstract view를 제공하는 것이다.
- Data Models: a collection of conceptual tools for describing data, data relationships, data sematics, and consistency constraints
(데이터 모델: 데이터, 데이터 관계, 데이터 의미, 일관성 제약 조건을 설명하기 위한 개념적인 도구 모음이다) - Data abstraction 데이터 추상화: Hide the complexity of data structures to represent data in the database from users through several levels of data abstraction.
(데이터 추상화: 여러 수준의 데이터 추상화를 통해 사용자로부터 데이터베이스의 데이터를 표현하기 위한 데이터 구조의 복잡성을 숨긴다.)
Data Models
Data, Data relationships, Data sematics, Data constraints를 설명하기 위한 도구 모음이다.
(데이터, 데이터 관계, 데이터 의미, 데이터 제약조건)
중요: Data Model의 종류!! Relational model을 아는지? SQL을 아는지?
Data Model의 종류
- Relational model 관계 모델
- Entity-Relationship data model 개체-관계 모델 (주로 DB 설계용)
- object-based data models
- semi-structured data model
- older: network model , hierarchical model
ER 모델은 추상적인 level의 모델. DB 설계 시 대부분 ER 모델링에서 시작한다. 기본적인 개체들(Entity들) 파악 가능.
보통 ER 모델로 개념적인 수준에서 작성한 뒤 Relational Model로 변환한다.
Relational Model (RM)
"Relational model" - 위키백과
- relation은 heading과 body로 구성된다.
- heading은 attributes의 set을 정의하는데, attribute 각각은 name과 data type(domain)이 있다. attributes의 수를 relation의 degree 또는 arity라고 한다.
- body는 tuples의 set이다. 각 tuple은 n가지(n=relation's arity) 값의 모음이다. tuple의 각 값은 unique attribute에 대응한다. tuples의 수를 relation의 cardinality라고 한다.
relation들은 relational variables(relvars)로 표현되고, 재할당될 수 있다. DB는 relvars의 모음이다.
모든 데이터들이 튜플로 표현되어, 다양한 테이블에 저장된다.
(관계형 모델의 표 형식 데이터 예시) instructor table의 구성: Columns, Rows
(관계형 데이터베이스의 간략한 예) department table의 dept_name을 instructor table이 FK로 가진다.
Levels of Abstraction
- Physical level 물리적 수준: describes how a record(e.g. instructor) is stored. 기록이 물리적으로 저장되는 방법.
- Logical level 논리적 수준: describes data stored in database, and the relationships among the data. DB에 저장된 데이터와 데이터 간의 관계를 설명한다.
- View level 보기 수준: 응용 프로그램은 데이터 유형의 세부 정보를 숨긴다. 보안을 위해 숨길 수도 있다.
View of Data
DB 시스템의 아키텍쳐
- View Level - view1, view2, view3...
- Logical Level: SQL 등 논리적인 구조. DB에서 어느 것에 초점을 맞출지. (Logical Level을 만듬으로써 물리적인 DB를 이전할 수 있다.)
- Physical level: 물리적인 저장. file... Oracel, IBM, MySQL, OS 등.
Instances and Schemas
- Logical Schema (논리적 스키마): 데이터베이스의 전반적인 논리적 구조.
(ex - DB는 은행의 고객, 계좌, 그리고 그들 사이의 관계에 대한 일련의 정보로 구성되어 있다. 프로그래밍 변수 타입 정보와 유사함.) - Physical Schema(물리적 스키마): 데이터베이스의 전반적인 물리적 구조.
- Instance(인스턴스): 특정 시점의 데이터베이스의 실제 내용. (변수의 값과 유사)
Instance는 특정 시점에서 전체 DB의 snapshot. (값 포함!)
- DB가 특정한 시간에서 실제 가지고 있는 콘텐츠. (값이 바뀌면 인스턴스가 바뀐 것임.)
Schema는 structure.
- Logical Schema가 우리가 고민하는 부분. 어떤 컬럼, 변수 타입.
- Physical Schema는 DB가 알아서 해준다.
Physical Data Independence
(물리적 데이터 독립성) 논리적 스키마를 건드리지 않고 물리적 스키마를 변경할 수 있는 능력.
- 응용은 logical schema에 의존한다.
Data Definition Language (DDL)
데이터베이스 스키마를 정의하기 위한 규격 표기법.
create table instructor ( -- table 생성
ID char(5), name varchar(20), dept_name varchar(20), salary numeric(8,2))
--각 column들의 name, type을 지정- DDL 컴파일러는 data dictionary에 저장될 테이블 템플릿 세트를 생성한다.
- Data dictionary는 metadata를 포함한다. (data에 대한 data - 아래의 것들)
- Database schema
- Integrity constraints 무결성 제약조건 (ex. PK)
- Authorization 권한 (누가 어떤 정보 접근?)
Data Manipulation Language (DML)
(적절한 데이터 모델에 의해 구성된) 데이터에 접근 및 갱신하기 위한 언어.
- DML의 두 유형: Procedural DML, Declarative DML
- Procedural DML: 사용자가 필요한 데이터와 해당 데이터를 얻는 방법을 명시해야 한다.
- Declarative DML: 사용자가 해당 데이터를 얻는 방법을 지정하지 않고 필요한 데이터를 명시해야 한다. (사용하기 더 쉽다. non-procedural DML)
- DML에서 정보 검색과 관련된 부분을 query language(질의어)라고 한다.
SQL Query Language ★★★
SQL query language는 nonprocedural이다. (SQL은 Declarative DML)
- query는 테이블들을 입력으로 사용하고, 항상 단일 테이블을 반환한다.
ex. select name from instructor where dept_name='Comp. Sci.'- SQL은 Turing machine equivalent language가 아니다. 루프 기능 x. 복잡한 함수를 계산하기 위해 SQL은 일반적으로 고급 언어에 임베디드 되어있다.
- 응용 프로그램은 일반적으로 다음 중 하나를 통해 DB에 접근한다.
(1) 임베디드 SQL을 허용하는 language extensions
(2) SQL 쿼리를 DB로 보낼 수 있는 Application program interface (ex. ODBC, JDBC)
Database Access from Application Program
SQL을 비롯해 nonprocedural query languages는 사용자의 입력, 출력, 디스플레이, 네트워크 통신 등의 작업을 지원하지 않는다. 이러한 계산 및 작업은 host language로 작성되어야 한다. (C/C++, Java, Python 등) DB의 데이터에 접근하는 embedded SQL queries와 함께.
Application programs은 이러한 방식으로 DB와 상호작용하는 데 사용되는 프로그램들이다.
Database Design
데이터베이스의 일반 구조를 설계하는 과정은 다음과 같다.
- Logical Design: 데이터베이스 스키마를 결정한다.
- 어떤 속성을 DB에 기록? 어떤 관계 스키마를 가져야 하고 다양한 관계 스키마들 사이에 속성을 어떻게 나눌지 - Physical Design: 데이터베이스의 물리적 레이아웃 결정
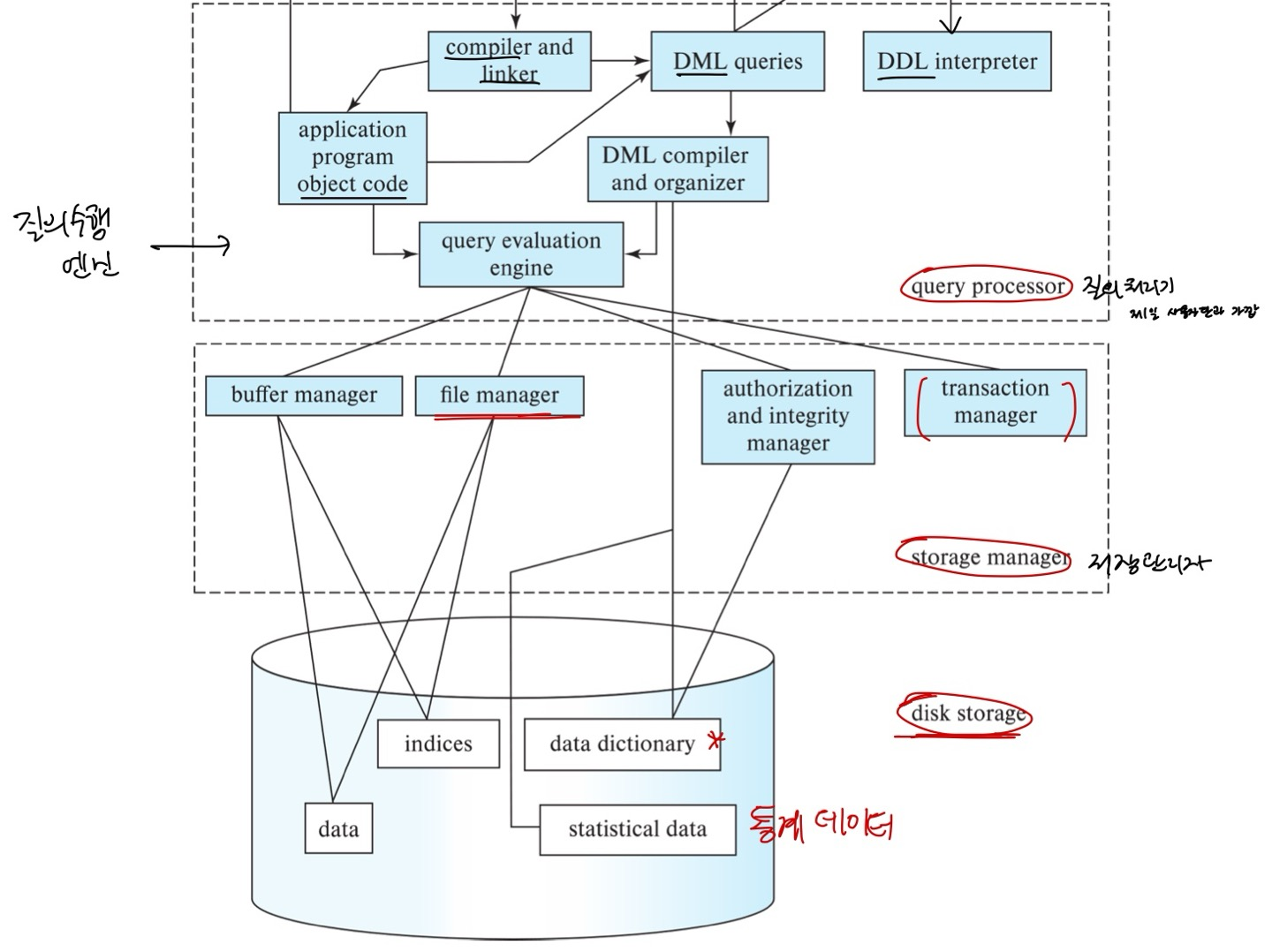
Database Engine
데이터베이스 시스템은 전체 시스템의 각 책임을 처리하는 모듈로 분할된다.
데이터베이스 시스템의 기능적 구성 요소:
1. storage manager - 저장소 관리자
2. query processor component - 질의 처리기
3. transaction management component - 트랜잭션 관리
(transaction: 한 처리. 여러 일을 한 묶음으로 하는 것. 일련의 과정들이 atomic하게 실행되도록)
Storage Manager 저장소 관리자
- DB에 저장된 저수준 데이터와 시스템에 제출된 응용 프로그램 및 쿼리 사이의 인터페이스를 제공하는 프로그램 모듈.
- SM은 다음 작업을 담당한다:
- OS 파일 관리자와의 상호작용
- 효율적인 데이터의 storing(저장), retrieving(검색), updating(갱신) -- SM이 데이터가 DB의 어디에 있는지를 안다.
- SM 컴포넌트는 포함한다:
- Authorization and integrity manager (보안 및 무결성 관리자)
- Transaction manager (트랜잭션 관리자)
- File Manager (파일 관리자)
- Buffer Manager (버퍼 관리자)
- SM은 물리적 구현 시스템의 일부로 여러 데이터 구조를 구현한다:
- Data files - DB 자체를 저장.
- Data Dictionary - DB 구조, 특히 DB 스키마에 대한 metadata를 저장. (테이블 크기, 정보 같은 것도 가짐)
- Indices(인덱스) - 데이터 항목에 대한 빠른 접근 제공 가능. 특정 값을 보유하는 항목에 대한 포인터를 제공한다. (추가적인 자료구조. B+tree 구조 많이 씀.)
Query Processor 질의 처리기
- 쿼리 프로세서 컴포넌트가 포함하는 것:
- DDL interpreter - (1) DDL문을 해석하고 (2) data dictionary에 정의들을 기록한다.
- DML compiler - query language로 된 DML문을 query evaluation engine이 이해할 수 있는 저수준 명령어들로 구성된 evaluation plan으로 번역한다.
- DML 컴파일러는 query optimization(질의 최적화)를 수행한다. 즉 비용이 가장 낮은 evaluation plan을 선택한다. (가장 적은 메모리. 시간.)
- evaluation plan(수행 계획): 쿼리를 처리하기 위해 필요한 작업들의 순서와 방법을 나타낸다.
- query evaluation engine - DML compiler에서 생성된 저수준 명령어들(query evaluation plan)을 실행한다.
Query Processing
DB에 질의 처리가 이루어지는 과정
1. Parsing and translation (구문 분석, 번역)
2. Optimization (최적화)
3. Evaluation (수행)
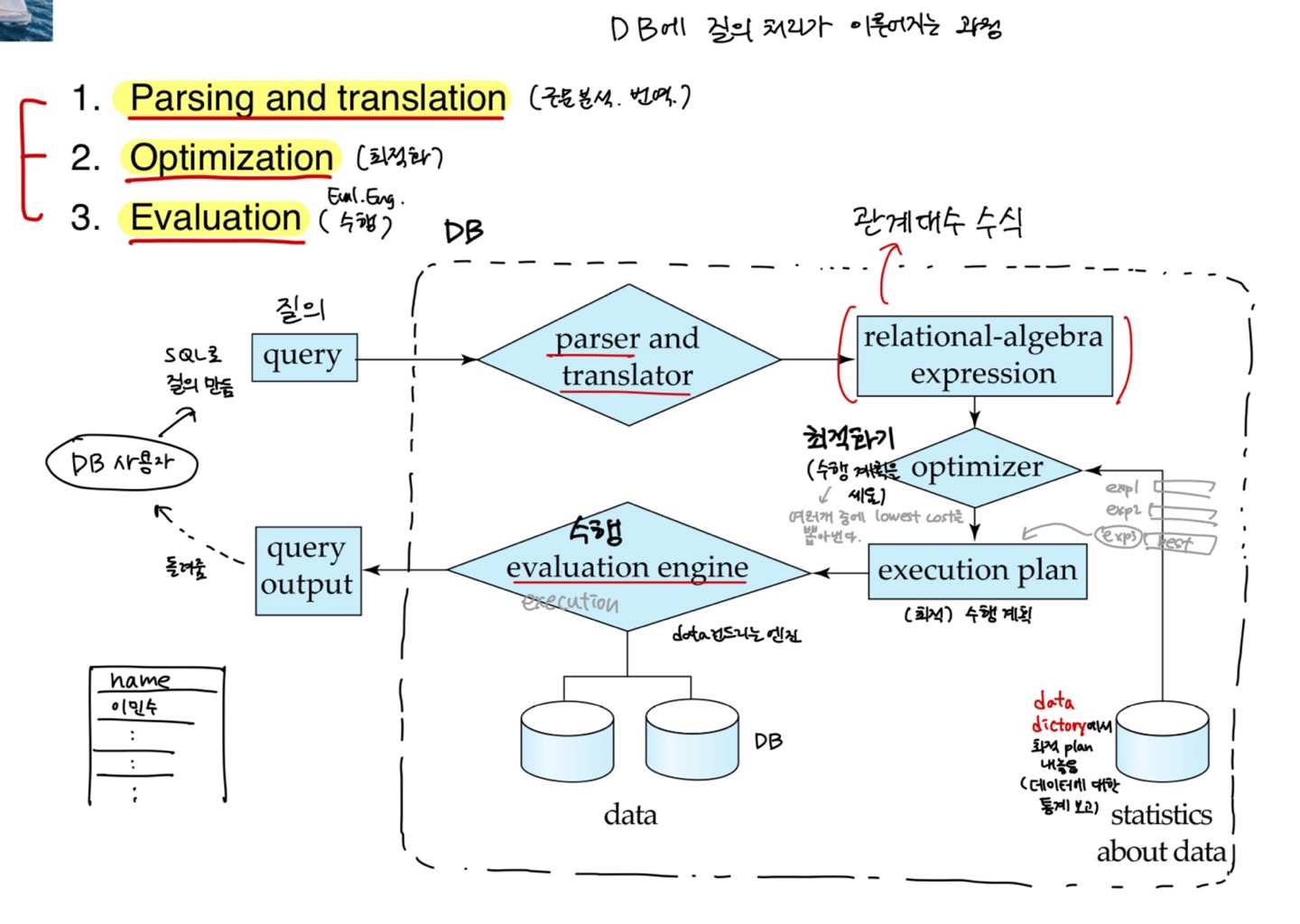
사용자가 SQL로 작성한 query ->
(1) parser와 translator(구문 분석기, 번역기) 로 전달되어 relational-algebra expression(관계대수 수식) 으로 변환
(2) optimizer(최적화기) 가 최적의 execution plan 을 도출(lowest cost)
(3) evaluation engine이 명령어들을 수행(DB 의 data를 건드리는 부분)
-> query output을 사용자에게 반환
Translation Management
- Transaction: 데이터베이스 애플리케이션에서 단일 논리적 기능을 수행하는 작업의 모음.
- atomicity: all or nothing - Transaction-management 컴포넌트: DB가 일관된 상태(consistent state)를 유지하도록 보장. (시스템 장애 및 트랜잭션 장애에도 불구하고)
- Concurrency-control manager 동시성 제어 관리자: DB의 일관성을 보장하기 위해 동시 트랜잭션(concurrent transactions) 간의 상호작용을 제어한다.
Database Architecture
- Centralized databases 중앙 집중식 (1개 또는 몇 개의 코어, shared memory)
- Client-Server 클라이언트-서버 (한 서버 머신이 여러 클라이언트를 대신해서 작업을 실행)
- Parallel databases 병렬 DB
1) 많은 수의 core, shared memory
2) shared disk -> 한 디스크를 여러 프로세서가 공유. Node들간 disk 공유 가능.
3) shared nothing -> 각 프로세서 단독 디스크. 독립적인 일을 병렬적으로. scalability 좋다. - Distributed databases 분산 DB
- Geographical disribution(통신 오버 헤드 있), Schema/data heterogenity
Database Architecture (Centralized / Shared-Memory)
- query processor 질의 처리기가 제일 사용자단과 가깝다.
- storage manager 저장소 관리자가 있고 transaction manager도 영역 안에 포함된다.
- 가장 아래의 disk storage에 data, indices, data dictionary, statistical data
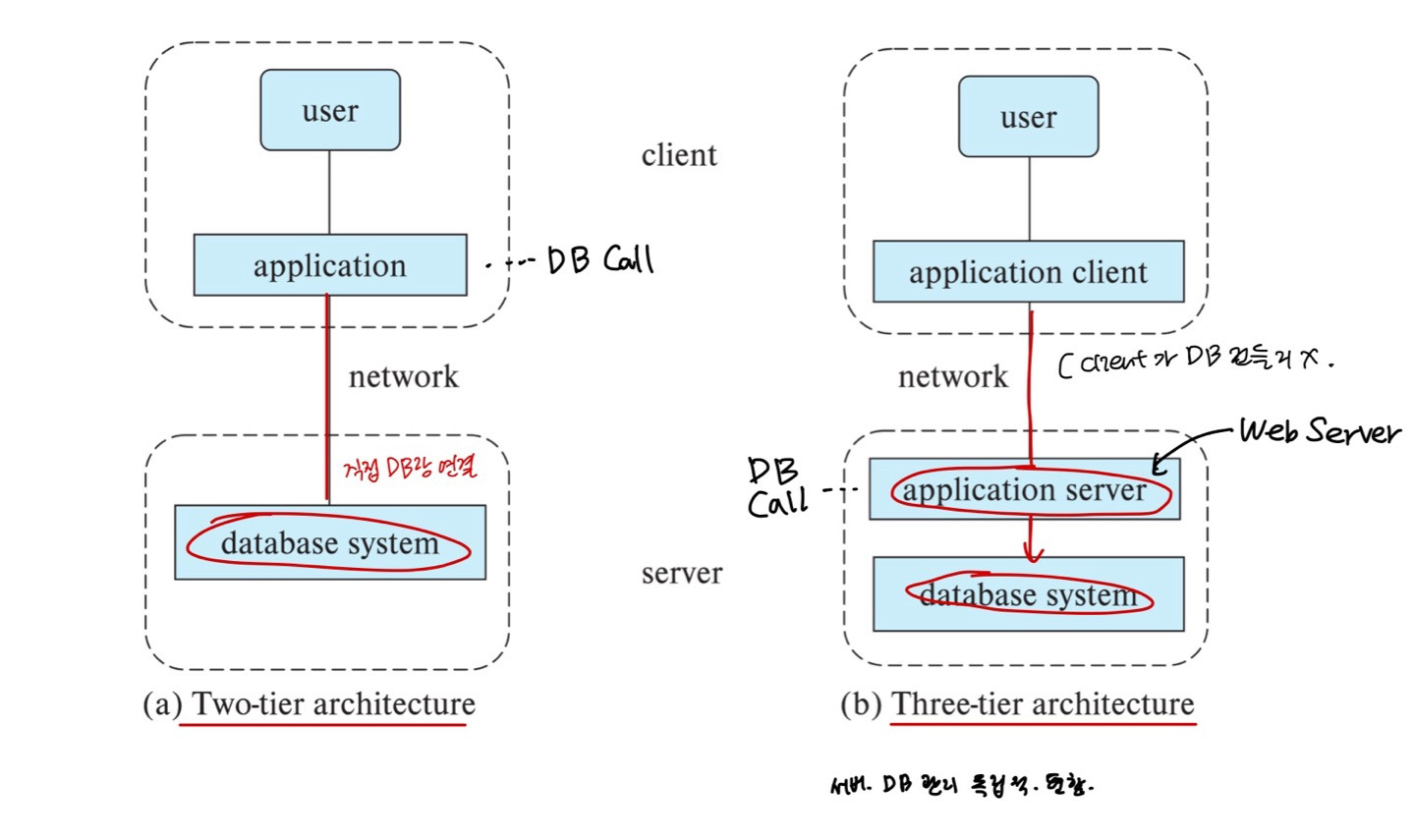
Database Applications - Two-tier and three-tier architectures
데이터베이스 애플리케이션은 일반적으로 2-3개 부분으로 분할된다.
- Two-tier 아키텍쳐: client에 application이 위치해 있고, 네트워크를 통해 server의 database system으로 직접 DB call을 보낸다.
- 애플리케이션이 client 컴퓨터에 상주하며, 데이터베이스 server 컴퓨터에게 직접 데이터를 요청하고 결과를 받아온다. (데이터베이스 시스템 기능을 직접 호출) - Three-tier 아키텍처: application client가 DB 호출하지 않는다. server에 위치한 application server가 DB call을 database system에 보낸다.
- client 컴퓨터가 직접 데이터베이스를 호출하지 않고, 대신 애플리케이션 server와 통신한다. 애플리케이션 server는 데이터베이스 시스템과 통신하여 데이터에 접근한다. (서버 DB 관리 독립적. 편함.)
Database Users
Database를 쓰는 사용자들. 그중 관리자도 있다.
Database Administrator
데이터베이스 관리자(DBA): 시스템의 중앙 제어 권한을 가진 사람.
DBA가 하는 일들:
스키마 정의, 저장소 구조 및 액세스 방법 정의, 스키마 및 물리적 구성 변경, 데이터 액세스 권한 부여, 일상적인 유지 보수, 데이터베이스 주기적 백업, 정상 작업을 위해 충분한 여유 디스크 공간 확보 및 필요 시 디스크 공간 업그레이드, 데이터베이스에서 실행 중인 작업 모니터링
History of Database Systems
(1960년대 후반과 1970년대) Ted Codd가 relational data model을 만들었다. IBM이 System R 프로토타입을 연구했다.
Oracle이 첫 상업적인 relational database를 출시했다.
'Subjects > 데이터베이스' 카테고리의 다른 글
| [데이터베이스] Chapter 5: Advanced SQL (0) | 2024.06.11 |
|---|---|
| [데이터베이스] 4. Intermediate SQL (0) | 2024.06.11 |
| [데이터베이스] 3. Introduction to SQL (2) (0) | 2024.06.11 |
| [데이터베이스] Chap 3. Introduction to SQL (0) | 2024.04.16 |
| [데이터베이스] Chap 2. Intro to Relational Model (0) | 2024.04.15 |



