
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
| 29 | 30 |
- AWS
- 스프링부트
- 게임개발동아리
- 전국대학생게임개발동아리연합회
- Spring boot
- 인프라
- UNIDEV
- 도커
- NAT gateway
- CICD
- Redis
- 생활코딩
- 티스토리챌린지
- 백엔드개발자
- UNICON
- 42서울
- 개발공부
- 프롬프트엔지니어링
- Route53
- springai
- 체크인미팅
- 라피신
- 오블완
- UNICON2023
- 프리티어
- 캡스톤디자인프로젝트
- EC2
- openAI API
- 프로그래밍
- bastion host
- Today
- Total
Hyun's Wonderwall
[데이터베이스] 3. Introduction to SQL (2) 본문
기말고사 범위 정리
Where Clause Predicates
* SQL은 "between" 비교 연산자를 포함한다
ex. select * from i where salary between 90000 and 100000
* 튜플 간 비교 - select * from instructor i, teaches t where (i.ID, dept_name) = (teaches.ID, 'Biology');
Set Operations
* A or B 찾기: 합집합. (select c_id from section where sem='Fall' and year=2017) union (select c_id from section where sem='Spring' and year=2018)
* A and B 찾기: 교집합. (select ~~~) intersect (select ~~~)
* A but not in B 찾기: (select ~~~) except (select ~~~)
* union, intersect, except - 자동적으로 중복을 제거한다. 중복을 유지하고 싶으면 all 붙이기. (union all, intersect all, except all)
Null Values
* null - 튜플의 속성값은 null value일 수 있음.
* null은 값이 존재하지 않거나 unknown임을 표시함.
* null을 포함하는 산술연산의 결과는 null. (ex. 5+null returns null)
* is null 은 속성이 널값인지 확인하는데 사용. is not null은 속성이 널값이 아닌지 확인하는데 사용.
각각 True인 경우만 뽑아진다.
ex. select name from inst where salary is null -> True: salary = null, False: salary <> null.
* SQL은 null을 포함하는 비교연산의 결과를 unknown으로 취급한다
* and, or, not을 계산할 때 unknown의 결과
* and - (true and unknown) = unknown, (false and unknown) = false, (unknown and unknown) = unknown
* or - (unknown or true) = true, (unknown or false) = unknown, (unknown or unknown) = unknown
* where 절에서 unknown으로 값이 나오면 false로 여겨진다.
Aggregate Functions 집계함수
- avg (평균값), min (최소), max (최대), sum (합), count (개수)
- select 절에 작성하며 multiset of values를 계산해 값을 반환한다.
Aggregate Functions Examples
* 컴공과 교수들의 평균 급여
- select avg (salary) from instructor where dept_name='Comp. Sci.' -> 평균값 1개 열만 출력됨.
* 2018년 봄에 강의를 가르친 교수의 숫자
- select count (distinct ID) from teaches where semester = 'Spring' and year = 2018; -> 중복을 제거해서 총 ID 개수가 반환된다
* course 관계의 튜플의 수
- select count (*) from course -> 튜플 총 개수가 출력된다 (=모든 컬럼을 기준으로 개수를 셈=모든튜플=테이블 크기)
Aggregate Functions – Group By
* 기준별로 grouping하는데, 이때 기준은 반드시 출력되어야 함
ex. 각각의 학과에 대해 교수들의 평균 급여 구하기 (group by dept_name)
select dept_name, avg (salary) as avg_salary from instructor
group by dept_name;
Attributes in select clause outside of aggregate functions must appear in group by list
-> select 절에 집계 함수를 쓸 때, 집계 함수 외부의 select 절에 있는 attribute는 group by 목록에 작성되어야 한다.
-> 뭔가를 group했으면 기준을 select 절에도 써야 한다.
(위에서 dept_name을 적지 않으면 안 되며, dept_name 말고도 ID 등을 쓰고 싶으면 group by에 적어줘야 함.)
Aggregate Functions – Having
* 평균 급여가 42000 이상인 모든 부서의 이름과 평균 급여 찾기 (group by dept_name having avg (salary) > 42000)
select dept_name, avg (salary) as avg_salary from instructor
group by dept_name having avg (salary) > 42000;필터링 순서: where -> group by -> having
(where은 그룹핑 하기 전에 적용되고 having은 그룹핑 한 후에 적용된다.)
Nested Subqueries 중첩 서브쿼리
SELECT A1, A2, ..., An FROM r1, r2, ..., rm WHERE P
- Select 절: Ai는 단일 값을 생성하는 아무 서브쿼리가 들어갈 수 있다.
- From 절: ri에는 아무 서브쿼리가 들어갈 수 있다.
- Where 절: P는 B <operation> (subquery) 형태가 들어갈 수 있다. (B는 속성)
- Set Membership -
* Find courses offered in Fall 2017 and in Spring 2018 -> 둘 다 열린 과목만.
select dinstinct course_id from section
where semester='Fall' and year=2017 and
course_id in (select course_id from section where semester='Spring' and year=2018);* Find courses offered in Fall 2017 but not in Spring 2018 -> 후자는 포함x
select distinct course_id from section
where semester='Fall' and year=2017 and
course_id not in (select course_id from section where semester='Spring' and year=2018);
주의... char이나 varchar에는 작은따옴표 붙이기. year에는 붙이면 안 됨!!
* Name all instructors whose name is neither “Mozart” nor “Einstein” -> name not in (튜플)
select distinct name from instructor where name not in ('Mozart', 'Einstein');
* Find the total number of (distinct) students who have taken course sections taught by the instructor with ID 10101
select count (distinct ID) from takes
where (course_id, sec_id, semester, year)
in (select course_id, sec_id, semester, year from teaches where teaches.ID=10101);
- Set Comparison -
Set Comparison – some Clause
* 누군가보다 크기만 하면 선택된다.
* Find names of instructors with salary greater than that of some (at least one) instructor in the Biology department.
-> Biology의 가장 낮은 임금 교수보다 임금이 큰 교수가 출력됨.
-- select distinct T.name from instructor T, instructor S
-- where T.salary > S.salary and S.dept_name='Biology';
-- some 절과 중첩쿼리를 사용하면
select name from instructor
where salary > some (select salary from instructor where dept_name='Biology');
Definition of “some” Clause
- (5 < some {0,5,6}) = true, (5 < some {0,5}) = false
- (5 = some {0,5}) = true, (5 ≠ some {0,5}) = true (이유: 0과 다르고 5와 같음)
'= some'은 in과 호환된다. 하지만 '≠ some'은 not in과 호환되지 않는다. (이유: 5 not in {0,5}은 false)
Set Comparison – all Clause
* Find the names of all instructors whose salary is greater than the salary of all instructors in the Biology department.
select name from instructor
where salary > all (select salary from instructor where dept_name='Biology');
Definition of “all” Clause
- (5 < all {0,5,6}) = false, (5 < all {6, 10}) = false
- (5 = all {4,5}) = false, (5 ≠ all {4,6}) = true (이유: 5 ≠ 4, 5 ≠ 6)
'≠ all'은 not in과 호환된다. 하지만 '= all'은 in과 호환되지 않는다.
Test for Empty Relations 공집합 검사
exists construct(제약조건)는 인자 서브쿼리가 nonempty이면 true를 반환한다.
- exists r <=> r != ∅ (공집합 아님)
- not exists r <=> r = ∅ (공집합임)
Use of “exists” Clause
* Find all courses taught in both the Fall 2017 semester and in the Spring 2018 semester
select course_id from section as S
where semester='Fall' and year=2017 and
exists (select * from section as T where semester='Spring' and year=2018 and S.course_id=T.course_id);correlation name - variable S in the outer query
correlated subquery 상관관계 서브쿼리 - the inner query
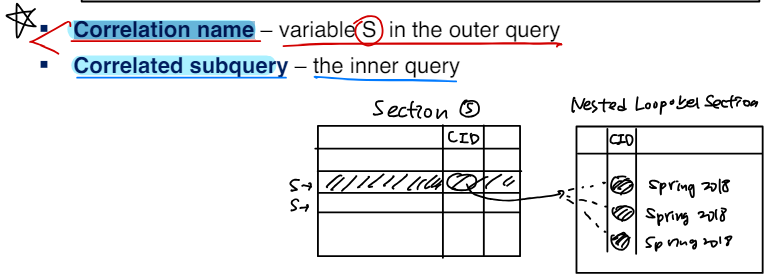
Use of “not exists” Clause
* Find all students who have taken all courses offered in the Biology department.
select distinct S.ID, S.name from student as S
where not exists ( (select course_id from course where dept_name='Biology')
except (select T.course_id from takes as T where S.ID=T.ID) );(생물학과에서 열린 모든 과목을 선택) 한 것에서 (학생 S가 수강한 모든 과목을 선택) 한 것을 except한 결과가
not exists 한지 검사->참이면 출력된다.
* X – Y = Ø <=> X⊆Y
* 이 쿼리를 = all 을 이용해서는 작성할 수 없다.
Test for Absence of Duplicate Tuples
* unique construct(제약조건)는 서브쿼리가 중복 튜플을 갖는지 검사한다. 중복이 없으면 true를 반환한다.
- 서브쿼리에서는 T 과목에 대해 2017년에 열린 분반들의 course_id를 나열하는데, 중복이 없으면 true이므로 선택된다. 즉 2017년에 분반이 1개만 열린 강좌를 나열하게 된다.
select T.course_id from course as T
where unique (select R.course_id from section ad R where T.course_id=R.course_id and R.year=2017);
From Clause 안에 서브쿼리를 작성하기
* Find the average instructors’ salaries of those departments where the average salary is greater than $42,000.
select dept_name, avg_salary
from (select dept_name, avg (salary) as avg_salary from instructor group by dept_name)
where avg_salary > 42000;
-- 또는
select dept_name, avg_salary
from (select dept_name, avg (salary) from instructor group by dept_name)
as dept_avg (dept_name, avg_salary)
where avg_salary > 42000;* 우리가 having 절을 쓸 필요 없음을 확인하자 (group by ... having .. 과 동일하게 가능)
* (서브쿼리) as dept_avg (dept_name, avg_salary) -> relation으로 table, column들 이름 renaming하였다.
* 제거하고 싶은 그룹들 삭제는 where 절로 삭제한다.
With Clause
"with 테이블명 (속성,...) as (nested subquery)"
* With 절은 temporary relation을 정의하여 사용하는 것으로, 해당 정의는 with 절이 있는 쿼리에서만 유효하다. (with 바로 뒤 select from where 하나에서만 쓸 수 있다)
* Find all department with the maximum budget -> 학과 중 최대 예산 "값"을 갖는 학과 찾기
with max_budget (value) as (select max(budget) from department)
select department.name from department, max_budget
where department.budget = max_budget.value;* 학과 중 최대 예산 "값"
With Clause을 사용하는 복잡한 쿼리
* Find all departments where the total salary is greater than the average of the total salary at all departments
- dept_total 테이블에 dept_name, value 컬럼 -> value 컬럼에 각 학과별 급여합이 저장되어있다.
- dept_total_avg 테이블에 value 컬럼 -> 첫 with 절에서 만든 dept_total을 사용하여 모든 학과의 평균 급여가 저장된다.
with dept_total (dept_name, value) as (select dept_name, sum(salary) from instructor group by dept_name),
dept_total_avg (value) as (select avg(value) from dept_total)
select dept_name from dept_total, dept_total_avg
where dept_total.value > dept_total_avg.value;-> 모든 학과 급여합의 평균보다 큰 학과들 이름들만 선택된다.
Scalar Subquery 스칼라 서브쿼리
* 단일 값을 반환하는 서브쿼리, 하나의 행(row)만 값처럼 반환한다.
* List all departments along with the number of instructors in each department.
select dept_name, (select count(*)
from instructor
where department.dept_name = instructor.dept_name
) as num_instructors
from department;
-- 사실 다음과 같다
-- SELECT dept_name, COUNT(*) AS num_instructors
-- FROM instructor
-- GROUP BY dept_name;-> 바깥변수와 내부변수 dept_name이 연결된다.
결과 튜플값이 하나 초과로 나오면 런타임 에러가 발생한다.
Modification of the Database
* 데이터베이스의 수정 - (1) 튜플 삭제 (2) 튜플 삽입 (3) 튜플의 값 업데이트
Deletion - "delete from r (where ~~ )"
* 전체 삭제: delete from r;
* where 절로 조건 주어 삭제: delete from instructor where dept_name='Finance';
* Delete all tuples in the instructor relation for those instructors associated with a department located in the Watson building:
delete from instructor
where dept_name in (select dept_name from department where building='Watson');* Delete all instructors whose salary is less than the average salary of instructors:
delete from instructor where salary < (select avg (salary) from instructor);
문제. 튜플을 삭제하는 과정에서 평균 급여가 변경될까?
* SQL의 솔루션: (1) 먼저 avg (salary)를 계산하고 삭제할 튜플을 모두 찾는다. (2) 찾아놓은 튜플을 모두 삭제한다. (avg를 다시 계산하지 않는다)
Insertion - "insert into r values (,,,) "
* 튜플 추가: insert into r values (속성 순서대로 각각 값들. 혹은 속성을 )
* null 값을 넣을 수도 있다. (물론 not null 제약조건 없는 경우)
insert into course values ('CS-437', 'Database Systems', 'Comp. Sci.', 4);
-- 속성을 명시적으로 적어줄 수 있다
insert into course (course_id, title, dept_name, credits) values ('CS-437', 'Database Systems', 'Comp. Sci.', 4);
insert into student values ('3003', 'Green', 'Finance', null); -- id는 varchar
* insert에 select from where 구문 사용하기: Make each student in the Music department who has earned more than 144 credit hours an instructor in the Music department with a salary of $18,000. (특정 조건을 만족한 학생이 같은과 교수가 되었다. ID도 유지한다.)
insert into instructor select ID, name, dept_name, 18000
from student
where dept_name='Music' and total_cred > 144;* 참고 - select from where 구문은 relation에 삽입되기 전에 결과가 완전히 계산되어서 넣어진다.
insert into table1 select * from table1;- 자기 자신을 읽어서 자신에게 넣는다 (re-evaluation) -> 추가할 부분 완전히 계산한 후에 넣어짐.
Updates - "update r set ~~ (where ~~) "
* 모든 대상에게 인상: update instructor set salary=salary*1.05
* 부등호로 비교해서 인상: update instructor set salary=salary*1.05 where salary < 70000;
* Give a 5% salary raise to instructors whose salary is less than average.
update instructor set salary = salary * 1.05
where salary < (select avg (salary) from instructor); -- 평균 급여* Increase salaries of instructors whose salary is over $100,000 by 3%, and all others by a 5%.
-- 100000초과 연봉자를 3% 인상한다
update instructor set salary = salary*1.03 where salary > 100000;
-- 100000이하 연봉자를 5% 인상한다
update instructor set salary = salary*1.05 where salary <= 100000;주의점: 쿼리가 나뉘어 있기 때문에 순서를 거꾸로 하면 연봉 인상을 2번 하게되니 주의.
* update, delete, insert 모두 순서 중요하다.
Case Statement for Conditional Updates - "case when ... then ... else ... end"
* case statement를 사용해서 하나의 쿼리로도 가능하다.
update instructor
set salary = case
when salary <= 100000 then salary * 1.05
else salary * 1.03
end
Updates with Scalar Subqueries
* DB에서 단 1개의 값을 반환한다.
* Recompute and update tot_creds value for all students:
update student S
set tot_cred = (select sum (credits) from takes, course
where takes.course_id = course.id and S.ID=takes.ID
and takes.grade<>'F' and takes.grade is not null);=> 아무 강의도 듣지 않은 학생의 tot_creds는 null이 된다.
* case문을 sum(credits) 대신 쓸 수 있다.
case
when sum(credits) is not null then sum(credits)
else 0
end
~ 테스트 ~
insert into student values ('testid', 'lsh', 'Comp. Sci.', 4);
insert into student (ID, name, dept_name, tot_cred) values ('testid2', 'lsh2', 'Comp. Sci.', 7);
-- 속성 작성 순서 바꿈
insert into student (ID, name, tot_cred, dept_name) values ('testid3', 'lsh2', 10, 'Comp. Sci.');
-- 이름 업데이트
update student set name = 'lsh3' where ID='testid3';
select * from student;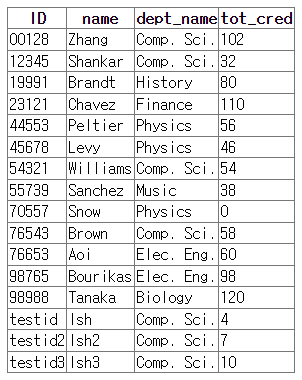
'Subjects > 데이터베이스' 카테고리의 다른 글
| [데이터베이스] Chapter 5: Advanced SQL (0) | 2024.06.11 |
|---|---|
| [데이터베이스] 4. Intermediate SQL (0) | 2024.06.11 |
| [데이터베이스] Chap 3. Introduction to SQL (0) | 2024.04.16 |
| [데이터베이스] Chap 2. Intro to Relational Model (0) | 2024.04.15 |
| [데이터베이스] Chap 1. Introduction (0) | 2024.04.14 |


