
Notice
Recent Posts
Recent Comments
Link
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
| 29 | 30 |
Tags
- Redis
- 프롬프트엔지니어링
- 개발공부
- UNIDEV
- 생활코딩
- EC2
- springai
- NAT gateway
- UNICON2023
- 42서울
- 프리티어
- 오블완
- 티스토리챌린지
- CICD
- 게임개발동아리
- 체크인미팅
- 인프라
- UNICON
- 스프링부트
- bastion host
- 프로그래밍
- Route53
- 도커
- 전국대학생게임개발동아리연합회
- Spring boot
- AWS
- 라피신
- 캡스톤디자인프로젝트
- 백엔드개발자
- openAI API
Archives
- Today
- Total
Hyun's Wonderwall
[데이터베이스] Chap 2. Intro to Relational Model 본문
Outline
- Structure of Relational Databases (관계 DB의 구조)
- Database Schema (DB 스키마)
- Keys (키. PK, FK)
- Schema Diagrams
- Relational Query Languages (관계 질의어)
- The Relational Algebra (관계대수)
Example of a Instructor Relation
- relation = table.
- attributes = columns. // relation에 여러개의 attributes가 있다
- tuples = rows. // relation 구성하는 data들, 하나하나의 행들. 순서 없음.
Relation Schema and Instance
- attributes: A1, A2, ..., An
- relation schema: R = (A1, A2, ..., An)
- ex) instructor = (ID, name, dept_name, salary)
- relation instance인 r은 스키마 R에서 r(R)로 정의된다
- the current values a relation are specified by a table
- relation r의 요소 t가 tuple. 테이블에서 row로 나타난다.
스키마: instructor(ID, name, dept_name, salary)
relation instance, schema에 대한 이해 조금 더 필요
Attributes
- 속성의 domain: 각 attribute에 대해 허용되는 값의 집합.
- attribute의 값은 atomic해야 한다 (indivisible해야 함.list, set 등 불가.)
- 특수 값 null은 모든 domain의 member이다. 이는 값이 "unknown"임을 나타난다.
- null 값으로 인해 많은 작업의 정의가 복잡해진다.
Relations are Unordered
- tuple들의 순서는 무관하다. (임의의 순서로 저장될 수 있다. irrelevant. arbitrary.)
- ex. instructor relation with unordered tuples
Database Schema
- Databse schema: database의 logical structure
- Database instance: snapshot of the data in the database at a given instant in time.
ex. schema: instructor(ID, name, dept_name, salary) - instance: r(R)이니까 r(instructor). 보면은 ID가 PK이다
Keys
- superkey가 되는 조건: K⊆R, 만약 K로 모든 가능한 릴레이션 r(R)의 튜플들을 고유하게 식별할 수 있다면 K는 R의 superkey.
ex. {ID}, {ID,name}은 (그리고 ID를 포함하는 복합키들은 모두) instructor의 superkey들이다. - K가 최소한의 속성들로 이루어진 경우, superkey K는 candidate key이다. (K가 후보 키로 선정되려면 최소한의 속성들로 이루어져야.)
- primary key: candidate key들 중 하나가 선택된다.
- Foreign key constraint: 한 relation에서 나타나는 값이 다른 relation에도 나타나야 한다.
- Referencing relation : 다른 relation의 key를(PK) 참조하는 쪽
- Referenced relation : 참조되는 쪽.
- ex) instructor의 dept_name은 FK이다: from instructor referencing department.
superkey(unique tuple 식별) -> candidate key(최소한인) -> primary key(하나를 선택)
Schema Diagram for University Database
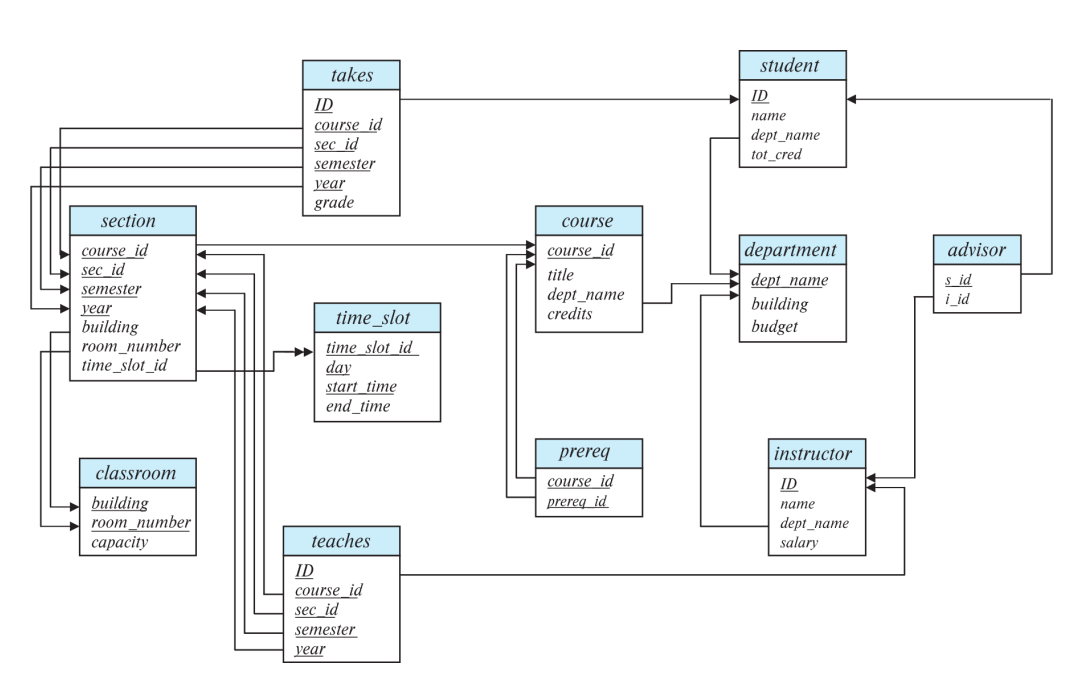
뭐부터 만들어야 하나? FK 없는 것부터
순서: classroom과 department과 time_slot
-> student와 instructor와 course
-> advisor과 prereq와 section
-> teaches와 takes
create table classroom (
building varchar(20),
room_number varchar(3),
capacity numeric(3, 0),
primary key (building, room_number)); -- building과 room_number가 복합키이다.
create table department (
dept_name varchar(20),
building varchar(20),
budget numeric(12, 2),
primary key (dept_name));
create table time_slot (
time_slot_id varchar(4),
day varchar(10),
start_time varchar(8),
end_time varchar(8),
primary key (time_slot_id, day, start_time)); -- time_slot_id, day, start_time이 복합키이다.create table student (
ID varchar(5),
name varchar(20) not null,
dept_name varchar(20),
tot_cred numeric(3,0),
primary key (ID),
foreign key (dept_name) references department);
create table instructor (
ID varchar(5),
name varchar(20) not null, -- comma 없음!!
dept_name varchar(20),
salary numeric(8,2),
primary key (ID),
foreign key (dept_name) references department);
create table course (
course_id varchar(8),
title varchar(50),
dept_name varchar(20),
credits numeric(2,0),
primary key (course_id),
foreign key (dept_name) references department);create table advisor (
s_id varchar(5),
i_id varchar(5),
primary key (s_id), -- 학생이 PK!!
foreign key (s_id) references student (ID),
foreign key (i_id) references instructor (ID));
create table prereq (
course_id varchar(8),
prereq_id varchar(8),
primary key (course_id, prereq_id),
foreign key (course_id) references course,
foreign key (prereq_id) references course (course_id)); -- 확인 필요
create table section (
course_id varchar(8),
sec_id varchar(8),
semester varchar(6),
year numeric(4,0),
building varchar(15),
room_number varchar(7),
time_slot_id varchar(4),
primary key (course_id, sec_id, semester, year),
foreign key (course_id) references course,
foreign key (building, room_number) references classroom,
foreign key (time_slot_id) references time_slot);create table teaches (
ID varchar(5),
course_id varchar(8),
sec_id varchar(8),
semester varchar(6),
year numeric(4,0),
primary key (ID, course_id, sec_id, semester, year),
foreign key (ID) references instructor,
foreign key (course_id, sec_id, semester, year) references section);
create table takes (
ID varchar(5),
course_id varchar(8),
sec_id varchar(8),
semester varchar(6),
year numeric(4,0),
grade varchar(2),
primary key (ID, course_id, sec_id, semester, year),
foreign key (ID) references student,
foreign key (course_id, sec_id, semester, year) references section);Schema Diagram에서 key를 파악하는 방법
- 밑줄이 있는 attribute들이 PK. (여러개라면 복합키.)
- 한 table에서 특정 속성이 나가는 화살표: 이 table이 연결된 table을 referencing하며 해당 속성을 FK로 가진다.
- 한 table에서 특정 속성이 들어오는 화살표: 이 table의 PK가 연결된 table에서 referenced 된다.
composite key: 복합키. 여러개의 attributes를 합쳐서 pk.
ex. takes의 PK는 {ID, course_id, sec_id, semester, year}.
table을 입력할 때는 반드시 참조되는 대상부터 넣어야 한다. (입력 순서가 중요함)
Relational Query Languages
- Procedural vs non-procedural(declarative) // 단계를 명시하는 절차적 vs 비절차적&선언적(<-only What. SQL도.)
- "Pure"한 언어: relational algebra, tuple relational calculus, domain relational calculus (세 언어는 computing power 동일)
- 우리는 relational algebra를 할 것임.
- Not Turing-machine equivalent.
- Consists of 6 basic operations (6개 연산. 그대로 SQL과 매핑 가능)
Relation Algebra 관계대수
- procedural language consisting of a set of operations that take one of two relations as input and produce a new relation as their result
- 하나 또는 두 개의 관계를 입력으로 받고 그 결과로 새 관계를 생성하는 일련의 작업으로 구성된 절차 언어.
- 6개의 기본 연산자: select, project, Cartesian product, union, set difference, rename
- 여러 연산자들을 엮음. 1개 또는 2개 relation(table)을 input으로 받아서 연산 -> 결과로 새 relation 도출 (또 연산 가능)
1. Select Operation σ
- Select 연산은 table을 대상으로 작동하며, 주어진 predicate(조건, 술어)을 만족하는 tuple들을 선택한다.
- 표기: σp(r) // p: selection predicate; r: relation
- ex "Physics" department에 있는 insturctor의 튜플들을 instructor relation에서 선택해보자.
Query: σdept_name="Physics"(instructor) // 1개 relation input.
(SQL로는) select * from instructor where dept_name='Physics' - 결과: 해당 경우를 만족하는 relation이 output으로 나온다
selection 연산은 SQL에서 where에 해당된다.
selection predicate에서 사용할 수 있는
비교연산자들: =, ≠, >, ≥, <, ≤
논리연산자들: ∧(and), ∨(or), ¬(not)
- ex. Physics에 있고 salary greater $90000인 instructor 찾기:
σdept_name="Physics"∧salary>90000(instructor)
selection predicate는 두 attributes간의 비교를 해야 할 수도 있다. - ex. find all departments whose name is the same as their building name
σdept_name=building(department)
2. Project Operation π
- Projection 연산은 relation의 특정 attributes를 출력하는 단항(unary) 연산이다.
- 표기: πA1,A2,A3...Ak(r) // A1, A2, ...An: attribute names; r: relation name
- 결과: k개 컬럼의 relation으로 정의된다 (적히지 않은 컬럼들을 지워서 얻어짐.) 세로로 열을 추출.
- 중복되는 행들은 결과에서 제거된다. 이유: Relations are sets.
- (projection 한 결과는 중복을 없애서 나타내게 된다. ex) dept_name 뽑았을 때. select distinct와 같은 효과.)
- (SQL로는) select A1, A2, A3...Ak from r
ex. eliminate the dept_name attribute of instructor
-> 관계대수: πID,name,salary(instructor)
-> SQL로는: select ID,name,salary from instructor
(이때 세 가지 조합 결과를 보았을때 유일성이 있어야 지워지지 않고 남음)
+ Composition of Relational Operations
- 관계 대수 연산의 결과는 relation이므로, 관계 대수 연산들은 relation-algera expression(관계 대수 표현)으로 합쳐질 수 있다.
- relation이 input이고 output이므로 조합해서 수식을 표현할 수 있다는 의미이다.
ex. Physics department에서 모든 instructors의 name을 찾을 때: πname(σdept_name="Physics"(instructor)) - projection 연산의 인수로 relation의 이름을 지정하는 대신에 우리는 결국 relation으로 evaluate되는 expression을 지정한다.
ex. select name from instructor where dept_name="Physics"
// select 하는 부분이 projection. from 하는 부분이 relation 선택 (cartesian product), where 하는 부분이 selection.
// sql 하는 절차는 db가 결정한다.
3. Cartesian-Product Operation X
- Cartesian-product 연산을 사용하면 두 relation의 정보를 결합할 수 있다.
- ex. instructor와 teaches의 relation들을 카테시안 곱 하면: instructor X teaches
- 결과 relation의 튜플은 두 relation으로부터 모든 가능한 튜플 조합들(쌍들)로 구성된다. (instructor의 튜플 + teaches 튜플 -> 한 결과 튜플)
- instructor.id, teaches.id: 교수의 ID가 instructor와 teaches 두 relation에서 나타나므로 relation의 이름을 붙여서 속성을 구분.
ex. instructor X teaches => SQL 돌렸을 때 결과 테이블에 ID 컬럼이 두 개 있는 것을 확인 가능.
근데 카테시안 곱은 두 relation 간 모든 튜플들을 결합시키기 때문에 교수가 가르치지 않은 과목도 조합된다.
(한 튜플에서 instructor.ID ≠ teaches.ID인 경우 있음) 실제로 가르친 과목만 보려면 select가 필요함 -> join operation.
4. Join operation ⋈
- Join 연산은 select 연산과 cartesian-product 연산을 한 연산으로 합친 것이다.
r ⋈𝜃 s = σ𝜃(r X s). // relation들 r(R), r(S) / 𝜃: 스키마 R "union" S의 attributes에 대한 조건
(두 테이블 union -> arributes 합쳐짐, tuple은 𝜃 조건에 따라 결합) - 따라서 교수와 그들이 가르친 과정과 관련된 튜플만 얻으려면:
σinstructor.id=teaches.id(instructor X teaches)
= instructor ⋈instructor.id=teaches.id teaches // 교수 ID가 같은 결합만 남김 - (SQL로는) select * from instructor,teaches where instructor.id=teaches.id
- from에서 comma 사용하는것이 cartestian product, 살아남을 애들을 join 조건으로 만든느 건데 행을 뽑아내는 것이어서 where에 한다.
SQLite 실습
select * from instructor;
select * from instructor, teaches wher instructor.ID=teaches.ID;5. Union Operation ∪ 합집합
- union 연산으로 두 relation을 결합할 수 있다.
- 표기: r ∪ s
- r ∪ s이 유효하려면 (가정)
- r, s는 같은 arity(같은 속성의 수)를 가져야 한다.
- 속성의 domain들은 compatible해야 한다. (값 타입이 같아야 한다)
- relation은 set 개념이기 때문에 1번, 2번 조건 만족하면 꺼낼 수 있다.
- ex. Fall 2017 또는 Spring 2018에 개설된 강의들 찾기:
section에서 찾은 후에 course_id를 꺼내야 함
πcourse_id(σsemester='Fall'∧year=2017(section)) ∪ πcourse_id(σsemester='Spring'∧year=2018(section))
6. Set-Intersection Operation ∩ 교집합
- set-intersection 연산으로 두 입력 relation들에서 공통적으로 나타나는 튜플들을 찾을 수 있다.
- 표기: r ∩ s
- r ∩ s이 유효하려면 (가정)
- r, s have the same arity (r, s가 같은 속성의 수를 가져야)
- attributes of r and s are compatible (r, s의 속성들이 서로 호환되어야)
- ex. Fall 2017과 Spring 2018 둘 다 열린 강의 찾기: πcourse_id(σsemester='Fall'∧year=2017(section)) ∩ πcourse_id(σsemester='Spring'∧year=2018(section))
7. Set Difference Operation - 차집합
- set-difference 연산은 한 relation에는 있고 다른 relation에는 없는 튜플을 찾을 수 있게 한다.
- 표기: r-s
- set-difference들은 compatible한 relations 간에 이루어져야 한다. (r과 s가 same arity(동일한 항)이고, r과 s의 속성 도메인들이 호환됨)
- ex. Fall 2017에는 열리고, Spring 2018에는 안 열린 강의 찾기: πcourse_id(σsemester='Fall'∧year=2017(section)) - πcourse_id(σsemester='Spring'∧year=2018(section))
8. The Assignment Operation ← 할당 연산
- 때로는 관계 대수식을 작성할 때 일부를 임시 변수에 할당하는 것이 필요하다.
- 할당 연산은 <- 로 표시되며 프로그래밍 언어의 할당과 같은 방식으로 작동한다.
- 할당 연산을 사용하면, 쿼리를 '일련의 할당과 쿼리 결과 값이 표시되는 식으로 구성된 순차적 프로그램'으로 작성할 수 있습니다.
- ex. find all instructor in the "Physics" and "Music" department
Physics <- σdept_name="Physics"(instructor)
Music <- σdept_name="Music"(instructor)
Physics ∪ Music // 쿼리 결과값 표시
9. The Rename Operation ρ 이름바꾸기
- 관계 대수 표현식의 결과는 참조할 수 없는 이름이 없어서 이름바꾸기 연산자 ρ가 제공된다.
- 표현: ρx(E) 은 표현식 E의 결과를 x라는 이름으로 반환한다.
- 또 다른 형식: ρx(A1,A2,...An)(E)
Equivalent Queries
- 관계대수에서 쿼리를 작성하는 방법은 한 가지가 아니다.
- 예시 1) 2개의 조건에 대해 selection 연산을 하려고 함
query 1: selection을 1번 하는데 selection predicate 2개를 ∧로 연결
query 2: selection을 2번 (따로따로)
=> 두 쿼리는 identical 하지 않지만 equivalent하다. 모든 데이터베이스에서 동일한 결과를 제공한다. - 예시 2) 물리학과의 강사가 가르치는 강좌에 대한 정보를 찾고자 함
query 1: (σdept_name="Physics"(instructor)) ⋈instructor.id = teaches.id teaches
query 2: σdept_name="Physics"(instructor ⋈instructor.id = teaches.id teaches)
=> 두 쿼리는 identical 하지 않지만 equivalent하다. 모든 데이터베이스에서 동일한 결과를 제공한다.
'Subjects > 데이터베이스' 카테고리의 다른 글
| [데이터베이스] Chapter 5: Advanced SQL (0) | 2024.06.11 |
|---|---|
| [데이터베이스] 4. Intermediate SQL (0) | 2024.06.11 |
| [데이터베이스] 3. Introduction to SQL (2) (0) | 2024.06.11 |
| [데이터베이스] Chap 3. Introduction to SQL (0) | 2024.04.16 |
| [데이터베이스] Chap 1. Introduction (0) | 2024.04.14 |
'Subjects/데이터베이스' Related Articles
more


