
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | ||||
| 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| 11 | 12 | 13 | 14 | 15 | 16 | 17 |
| 18 | 19 | 20 | 21 | 22 | 23 | 24 |
| 25 | 26 | 27 | 28 | 29 | 30 | 31 |
- Route53
- 프로그래밍
- UNICON2023
- 전국대학생게임개발동아리연합회
- 도커
- 체크인미팅
- 프롬프트엔지니어링
- EC2
- 개발공부
- 인프라
- Redis
- NAT gateway
- 생활코딩
- 스프링부트
- 42서울
- openAI API
- 라피신
- 오블완
- 프리티어
- spring ai
- 백엔드개발자
- UNICON
- 캡스톤디자인프로젝트
- bastion host
- AWS
- 티스토리챌린지
- 게임개발동아리
- UNIDEV
- CICD
- Spring boot
- Today
- Total
Hyun's Wonderwall
[AIchemist] 파머완 - CH04. 분류 (5~8, 11) 본문
AIchemist 1기
- 이화여대 머신러닝 입문 스터디
- 스터디 교재: 권철민, "파이썬 머신러닝 완벽 가이드"
- 4주차 과제: 파머완 p.221-p.307 (4장 5단원~8단원, 11단원)
[Chapter 04] 분류
5. GBM(Gradient Boosting Machine)
5.1. GBM의 개요 및 실습
* 부스팅 알고리즘: 여러 개의 약한 학습기(weak learner)를 순차적으로 학습-예측하면서 잘못 예측한 데이터에 가중치 부여를 통해 오류를 개선해 나가면서 학습하는 방식.
- AdaBoost, 그래디언트 부스트(GBM)가 대표적
* AdaBoost(에이다부스트) : 개별 분류기가 일으킨 오류 데이터에 가중치를 부여하면서 부스팅을 하는 알고리즘. 개별 약한 학습기들에 각각 가중치를 부여한 후 예측 데이터를 모두 결합해 예측을 수행한다.
* GBM : 경사 하강법(Gradient Descent)을 이용해 가중치 업데이트를 수행함.
** 경사 하강법(Gradient Descent) : 반복 수행을 통해 오류를 최소화할 수 있도록 가중치의 업데이트 값을 도출하는 기법.
'오류 값=실제 값-예측 값'이다. 피처를 x, 실제 결과값을 y, 예측 함수를 F(x)라 하면 오류식: h(x) = y - F(x). 오류식이 최솟값 되게.
GBM 기반의 분류 - GradientBoostingClassifier 클래스.
대체로 GBM이 랜덤 포레스트보다 예측 성능이 뛰어나지만, 수행 시간이 오래 걸리는 단점. 병렬 처리가 지원되지 않아 대용량 데이터의 경우 학습에 많은 시간이 필요. (랜덤 포레스트 수행 시간 빠름)
5.2. GBM 하이퍼 파라미터
트리 기반 파라미터(공통) 갖고있음
- loss : 경사 하강법에서 사용할 비용 함수 지정 (기본: deviance)
- learning_rate : GBM이 학습을 적용할 떄마다 적용하는 학습률. 약한 학습기가 순차적으로 오류값을 보정하는데 적용. (0~1사이의 값, 기본: 0.1)
- n_estimators : weak learner의 개수 (개수가 많아질 수록 예측 성능이 좋아질 수 있음.(일정 수준까지) 개수가 너무 많아지면 수행 시간이 오래 걸림. 기본값은 100)
- subsample : weak learner가 학습에 사용하는 데이터의 샘플링 비율. (기본값은 1 = 전체 학습 데이터를 기반으로 학습한다는 의미. 과적합 염려시 1보다 작은 값으로 설정.)
6. XGBoost(eXtra Gradient Boost)
6.1. XGBoost 개요
트리 기반의 앙상블 학습에서 가장 각광받는 알고리즘 중 하나. GBM에 기반해서 단점을 보완함.
분류와 회귀 영역에서 뛰어난 예측 성능, 병렬 수행 등 다양한 기능으로 GBM에 비해 빠른 수행 속도, 과적합 규제 기능, 나무 가지치기(True Pruning- 긍정 이득이 없는 분할 줄임), 교차 검증 자체 내장, 결손값 자체 처리도 갖춤.
(초기-파이썬만 되는) 파이썬 래퍼 XGBoost 모듈 : 사이킷런과 호환x
(최근-사이킷런 연동) 사이킷런 래퍼 XGBoost 모듈 : 표준 사이킷런 개발 프로세스, 유틸리티 사용가능. XGBClassifier, XGBRegressor 클래스
6.2. XGBoost 설치
6.3. 파이썬 래퍼 XGBoost의 하이퍼 파라미터
- 일반 파라미터 : 스레드 개수, silent 모드 선택 등.. 디폴트 파라미터 값을 바꾸는 경우는 거의 없음
(주요) booster, silent, nthread - 부스터 파라미터 : 트리 최적화, 부스팅, regularization 등과 관련 파라미터 등을 지칭
(주요) eta, num_boost_rounds, min_child_weight, gamma, max_depth, sub_sample, colsample_bytree, lambda, alpha, scale_pos_weight - 학습 태스크 파라미터 : 학습 수행 시의 객체 함수, 평가를 위한 지표 등을 설정
(주요) objective, binary:logistic, multi:softmax, multi:softprob, eva_metric, rmse, mae, logloss, error, merror, mlogloss, auc
과적합 문제가 심각하다면 적용할 수 있는 방법들
eta값감소, max_depth감소, min_child_weight감소, min_child_weight감소, gamma높임, subsample과 colsample_bytree조정..
XGBoost의 여러 성능 향상 기능들 ex. 초기 중단 : 수행 속도 향상
6.4. 파이썬 래퍼 XGBoost 적용 - 위스콘신 유방암 예측
6.5. 사이킷런 래퍼 XGBoost의 개요 및 적용
하이퍼 파라미터 - 파이썬 래퍼 XGBoost와 이름이 다른 경우들 존재.
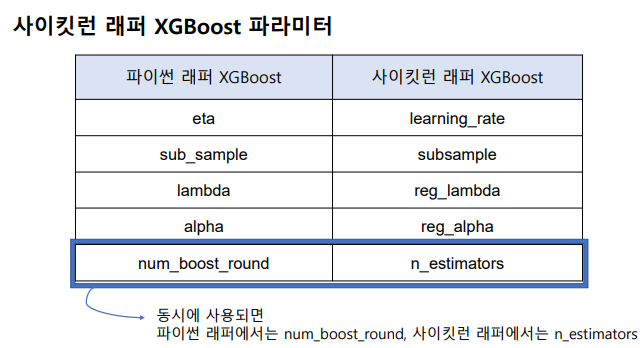
초기 중단 수행 가능 - early_stopping_rounds, eval_metric, eval_set
7. LightGBM
LGBM의 XGBoost 대비 장점
- 빠른 학습과 예측 수행 시간, 더 적은 메모리 사용량
- 예측 성능은 비슷하지만 기능상 더 다양하다
- 카테고리형 피처의 자동 변환과 최적 분할
LightGBM 특징: 리프 중심 트리 분할(Life Wise) 방식 사용.
Life Wise 방식: 최대 손실값 가지는 리프 노드를 지속적으로 분할하면서 학습하고, 균형 트리 방식보다 예측 오류 손실을 최소화할 수 있다. (기존의 대부분 트리 기반 알고리즘은 균형 트리 분할(Level Wise) 방식 사용)
LightGBM의 단점: 적은 데이터 세트(일반적으로 1만 건 이하)에 적용할 경우 과적합이 발생하기 쉬움
7.1. LightGBM 설치
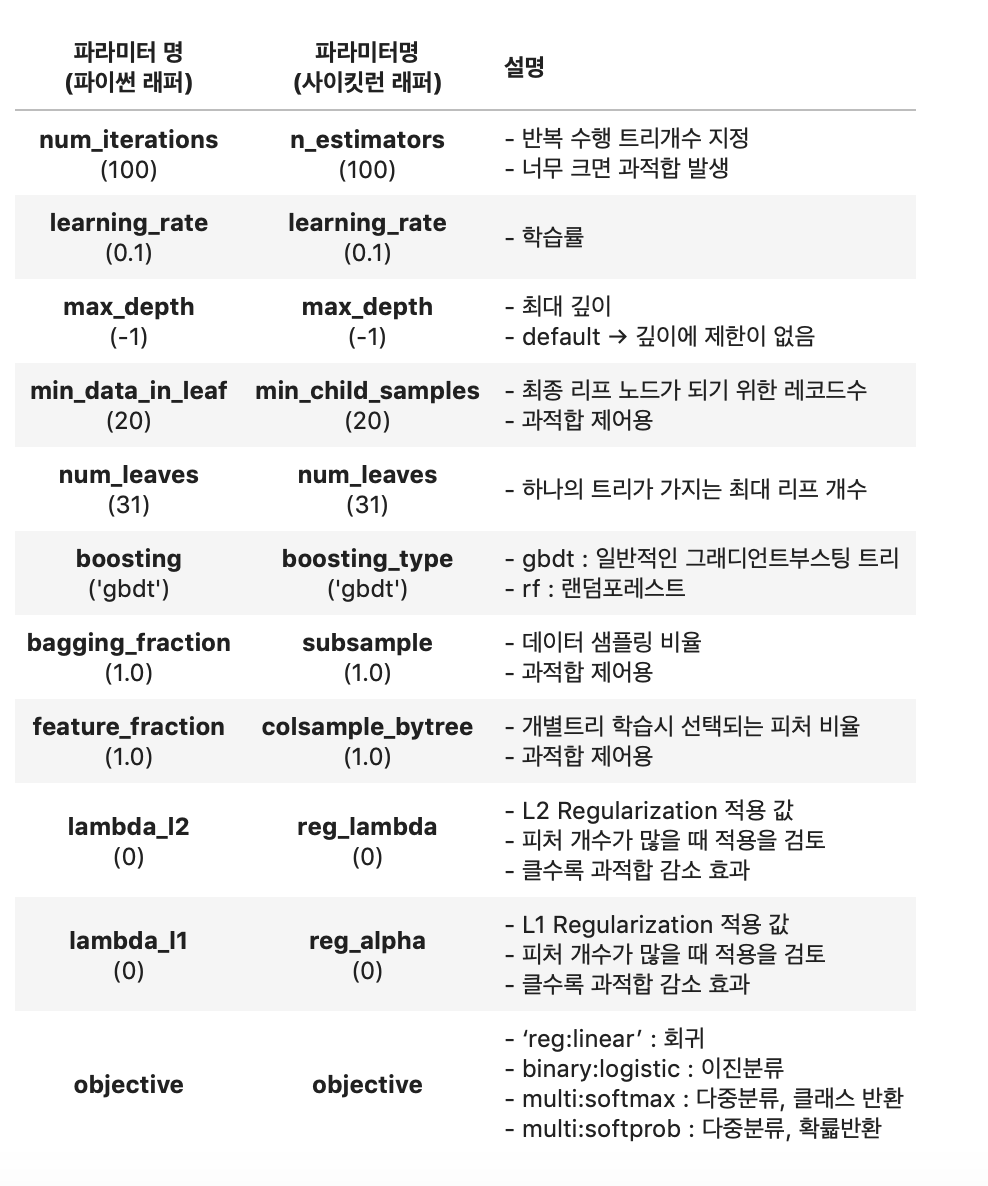
7.2. LightGBM 하이퍼 파라미터
주의할 점: LightGBM은 리프 노드가 계속 분할되면서 트리의 깊이가 깊어지므로 그 특성에 맞는 하이퍼 파라미터 설정이 필요하다. (ex. max_depth를 매우 크게)
주요 파라미터
- num_iterations [ default = 100] : 반복 수행하려는 트리의 개수를 지정.
- learning_gate [ default = 0.1] : 부스팅 스텝을 반복적으로 수행할 때 업데이트되는 학습률 값. 0~1 사이 값 지정.
- max_depth [ default = -1 ] : 트리 기반 알고리즘의 max_depth와 동일.
- min_data_in_leaf [ default = 20 ] : 결정 트리의 min_samples_leaf와 동일
- num_leaves [ default = 31 ] : 하나의 트리가 가질 수 있는 최대 리프 개수
- boosting [ default = gbdt ] : 부스팅의 트리를 생성하는 알고리즘을 기술 (gbdt / rt)
- bagging_fraction [ default = 1.0 ] : 트리가 커져서 과적합되는 것을 제어하기 위해서 데이터를 샘플링하는 비율을 지정. (XGBClassifier의 subsample 파라미터와 동일하고 LightGBMClassifier에서는 subsample로 파라미터 이름 변경됨)
- feature_fraction [ default = 1.0 ] : 개별 트리를 학습할 때마다 무작위로 선택하는 피저의 비율 (과적합을 막기 위해 사용됨. (XGBClassifier의 colsample_bytree 파라미터와 동일하고 LightGBMClassifier에서는 colsample_bytree로 변경됨)
- lambda_l2 [ default = 0.0 ] : L2 regulation 제어를 위한 값. 피처 개수 많을 경우 적용 검토, 값이 클수록 과적함 감소. (XGBClassifier의 reg_lambda 파라미터와 동일하고 LightGBMClassifier에서는 reg_lambda로 변경됨)
- lambda_l1 [ default = 0.0 ] : L1 regulation 제어를 위한 값. 과적합 제어 위해. (XGBClassifier의 reg_alpha 파라미터와 동일하고 LightGBMClassifier에서는 reg_alpha로 변경됨)
Learning Task 파라피터
- objective: 최솟값을 가져야 할 손실함수를 정의한다. XGBoost의 objective 파라미터와 동일. 어떤 유형인지에 따라 손실함수가 지정된다.
7.3. LGBM 하이퍼 파라미터 튜닝 방안
num_leaves의 개수를 중심으로 min_child_samples(min_data_in_leaf), max_depth를 함께 조정하면서 모델의 복잡도를 줄이는 것이 기본 튜닝 방안.
learning_rate를 작게 하면서 n_estimators를 크게 하는 것은 부스팅 계열 튜닝에서 가장 기본적인 튜닝 방안. 이를 적용하는 것도 좋다.
이밖에 regularization 적용하거나 colsample_bytree, subsample 파라미터 적용가능
7.4. 파이썬 래퍼 LigthGBM과 사이킷런 래퍼 XGBoost, LigthtGBM 하이퍼 파라미터 비교
7.5. LigthGBM과 적용 - 위스콘신 유방암 예측
8. 베이지안 최적화 기반의 HyperOpt를 이용한 하이퍼 파라미터 튜닝
XGBoost나 LightGBM의 하이퍼 파라미터 튜닝 시에 GridSearch 단점 존재. 베이지안 최적화를 사용하자.
8.1. 베이지안 최적화 개요
베이지안 최적화 : 목적 합수 식을 제대로 알 수 없는 블랙 박스 형태의 함수에서 최대 또는 최소 함수 반환 값을 만드는 최적 입력값(최적 함수)을 효과적으로 찾아주는 방식.
*중요 요소 : 대체 모델, 획득 함수
- 대체 모델 : 획득 함수로부터 최적 함수를 예측할 수 있는 입력값을 추천받고 이를 바탕으로 최적 함수 모델을 개선해 나감
- 획득 함수 : 개선된 대체 모델을 기반으로 최적 입력값을 계산함

8.2. HyperOpt
베이지안 최적화를 '하이퍼 파라미터 튜닝'에 적용할 수 있도록 제공되는 파이썬 패키지. 목적 함수 반환값의 최솟값을 가지는 최적 입력값을 유추.
*활용 로직 : (1)입력 변수명과 입력값의 검색 공간 설정 / (2)목적 함수 설정 / (3)목적 함수의 반환값이 최솟값을 가지도록 하는 최적 입력값 유추
8.3. HyperOpt를 이용한 XGBoost 하이퍼 파라미터 최적화
11. 스태킹 앙상블
스태킹은 개별적인 여러 알고리즘을 서로 결합해 예측 결과를 도출한다. 가장 큰 차이점: 개별 알고리즘으로 예측한 데이터를 기반으로 다시 예측을 수행함 (즉, 개별 알고리즘의 예측 결과 데이터 세트를 최종 메타 데이터 세트를 만들어 별도의 ML 알고리즘으로 최종 학습을 수행하고 -> 테스트 데이터를 기반으로 해서 학습하고 예측하는 방식(메타 모델))
스태킹에는 두 종류의 모델이 필요
1. 개별적인 기반 모델
2. 최종 메타 모델 (이 개별 기반 모델의 예측 데이터를 학습 데이터로 만들어서 학습)
*스태킹 모델의 핵심: 여러 개별 모델의 예측 데이터를 각각 스태킹 형태로 결합해 최종 메타 모델의 학습용 피처 데이터 세트와 테스트용 피처 데이터 세트를 만드는 것.
조금이라도 성능 수치를 높여야 할 경우 자주 사용된다.
11.1. 기본 스태킹 모델
11.2. CV 세트 기반의 스태킹
Step 1: 각 모델별로 원본 학습/테스트 데이터를 예측한 결과값을 기반으로 메타 모델을 위한 학습용/테스트용 데이터를 생성
Step 2: 스텝1에서 개별 모델들이 생성한 학습용 데이터를 모두 스태킹 형태로 합쳐서 메타 모델이 학습할 최종 학습용 데이터 세트를 생성
스태킹 모델은 회귀에도 적용 가능.
'Study > Python-Machine-Learning' 카테고리의 다른 글
| [AIchemist] 파머완 - CH04. 분류 | 10. 캐글 신용카드 사기 검출 (0) | 2023.10.31 |
|---|---|
| [AIchemist] 파머완 - CH04. 분류 | 09. 캐글 산탄데르 고객 만족 예측 (0) | 2023.10.31 |
| [AIchemist] 파머완 - CH03. 평가 (6. 피마 인디언 당뇨병 예측) (0) | 2023.10.09 |
| [AIchemist] 파머완 - CH03. 평가 (1~5) (0) | 2023.09.26 |
| [AIchemist] 파머완 - CH02. 사이킷런으로 시작하는 머신러닝 (6. 사이킷런으로 수행하는 타이타닉 생존자 예측) (0) | 2023.09.25 |


